JAVA并发锁:
1.java实现线程的方式:
1)继承Thread类:
/*继承Thread并重写run方法*/
public class MyThread extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行");
}
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName() + "执行");
MyThread thread = new MyThread();
thread.start();
}
}2)实现Runnable接口:
/*实现Runnable接口,重写run方法,通过Thread对象调用*/
public class MyRunnable implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行");
}
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName() + "执行");
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();
}
}3)实现Callable接口:
/*实现Callable接口*/
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(3000);
return "hello world";
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> future = new FutureTask<>(new MyCallable());
Thread thread = new Thread(future);
thread.start();
//future.get()会阻塞获取线程执行的结果
System.out.println(future.get());
}
}为什么Thread能够接收FutureTask对象?


FutureTask类实现RunnableFuture接口,RunnableFuture接口实现Runnable接口;并且重写run方法,在run方法中调用了call方法。
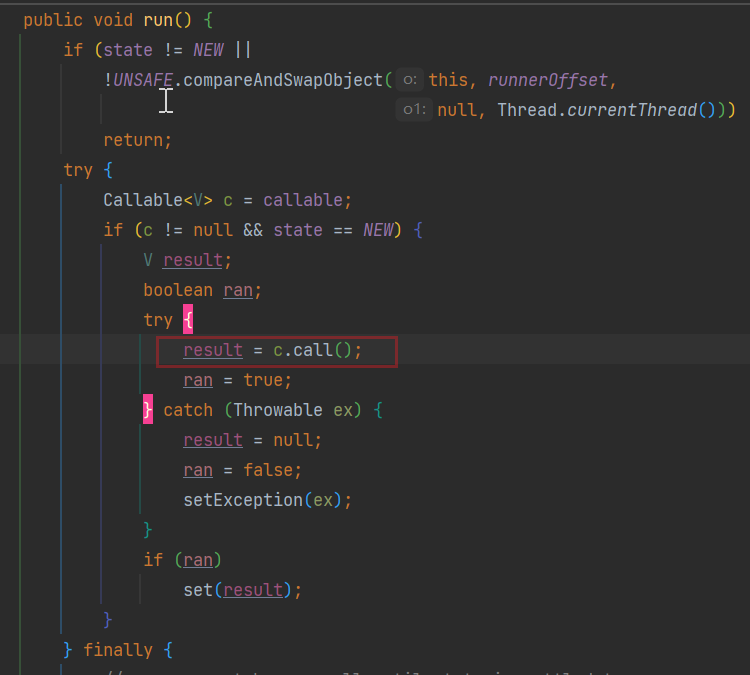
总结:不管那种方式实现的线程,创建线程并且执行线程只能是Thread对象;
run()和statr()的区别:
run方法只是一个类的普通方法,并不会创建一个新的线程,start方法是调用本地方法创建一个新的线程并且执行run方法。
2.为什么会出现并发安全问题:
java并发安全是jvm虚拟机线程运行机制造成的;在jvm虚拟机中多个线程访问同一变量,每个线程会把共享内存中的值读到自己的工作内存中,并且修改自己操作内存中的值,修改完成后再写回共享内存中;在这个过程中,多个线程可能再同一时刻读取到相同的值,并且执行操作,在回写的过程可能会出现前面线程回写的值被后面线程覆盖的情况,从而导致并发安全问题。
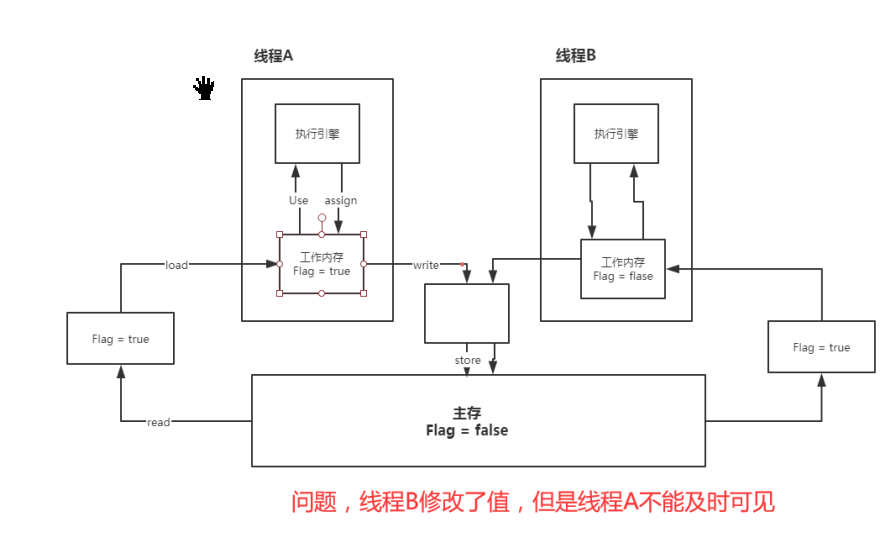
lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态;
unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量
才可以被其他线程锁定;
read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便
随后的load动作使用;
load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中;
use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机
遇到一个需要使用到变量的值,就会使用到这个指令;
assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变
量副本中;
store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,
以便后续的write使用;
write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内
存的变量中。不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须
write
不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
不允许一个线程将没有assign的数据从工作内存同步回主内存
一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量
实施use、store操作之前,必须经过assign和load操作
一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解
锁
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,
必须重新load或assign操作初始化变量的值
如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
对一个变量进行unlock操作之前,必须把此变量同步回主内存3.解决并发安全问题:
解决并发安全问题只能加锁synchronized或者Lock类;
volatile关键字虽然无法解决并发安全问题,但是可以保证内存的可见性。
1)synchronized关键字:
public class SynchronizedDemo {
/*同步方法,锁对象是this*/
public synchronized void testA() {
}
/*同步静态方法,锁对象是SynchronizedDemo.class对象*/
public static synchronized void testB() {
}
/*同步代码块,可以随意指定锁对象*/
public void testC() {
synchronized (this) {
}
}
}分析testC方法字节码:
0 aload_0
1 dup
2 astore_1
3 monitorenter //添加监控方法,加锁
4 aload_0
5 dup
6 getfield #2 <org/test/juc/SynchronizedDemo.count : I>
9 iconst_1
10 iadd
11 putfield #2 <org/test/juc/SynchronizedDemo.count : I>
14 aload_1
15 monitorexit //退出监控方法,释放锁
16 goto 24 (+8)
19 astore_2
20 aload_1
21 monitorexit
22 aload_2
23 athrow
24 returnsynchronized同步代码块会在操作的代码前后加入monitorenter和monitorexit操作;
执行monitorenter指令时,线程会为锁对象关联一个ObjectMonitor对象:
objectMonitor.cpp
ObjectMonitor() {
_header = NULL;
_count = 0; \\用来记录该线程获取锁的次数
_waiters = 0,
_recursions = 0; \\锁的重入次数
_object = NULL;
_owner = NULL; \\当前持有ObjectMonitor的线程
_WaitSet = NULL; \\wait()方法调用后的线程等待队列
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; \\阻塞等待队列
FreeNext = NULL ;
_EntryList = NULL ; \\synchronized 进来线程的排队队列
_SpinFreq = 0 ;
_SpinClock = 0 ; \\自旋计算
OwnerIsThread = 0 ;
}在java8中对synchronized进行了优化,java8之前的synchronized添加的是重量级锁;优化了之后的synchronized加入了锁升级机制,锁升级也就是在锁对象的对象头添加标记:
对象头:
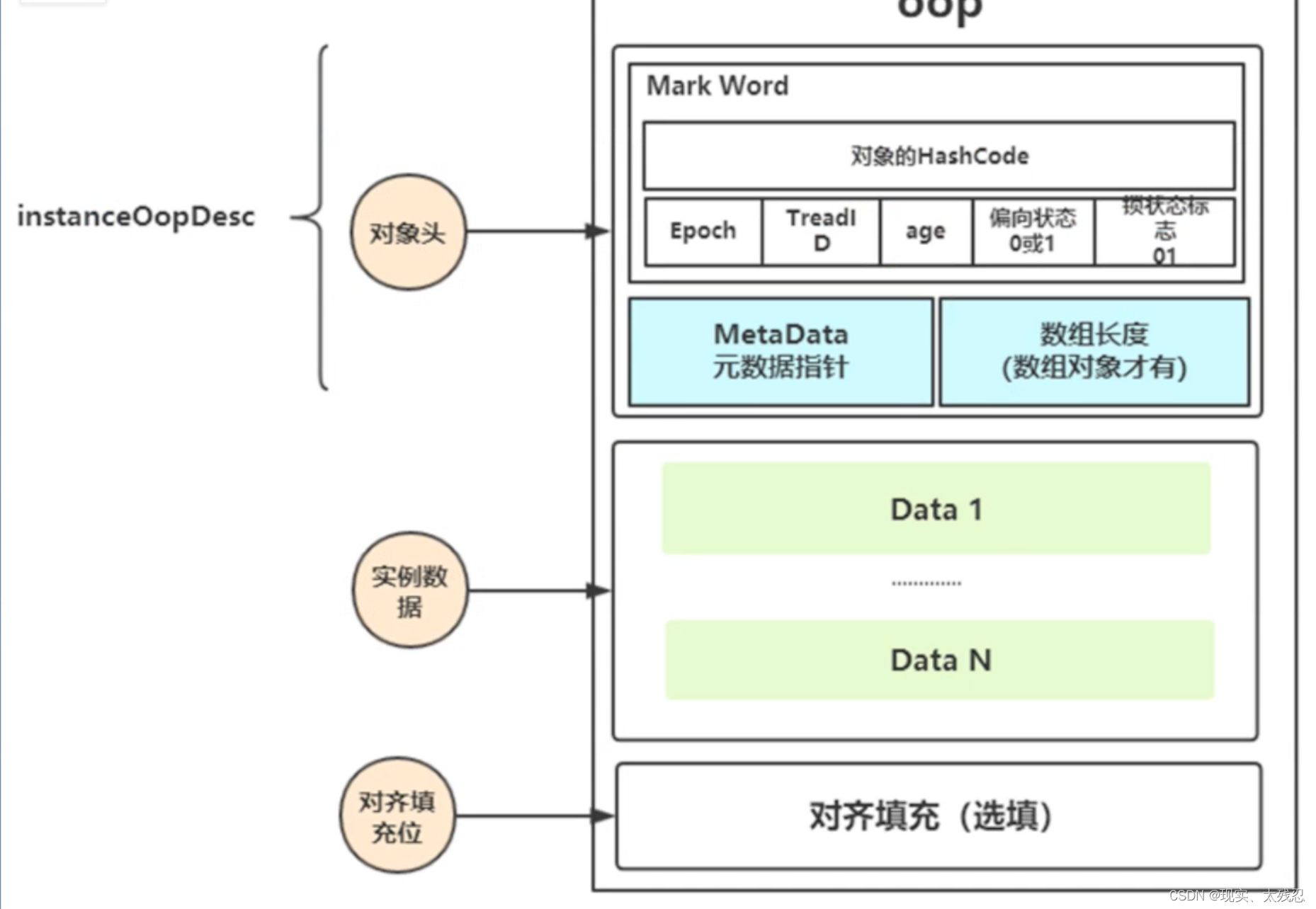
在对象头中的Mark Word添加标记:
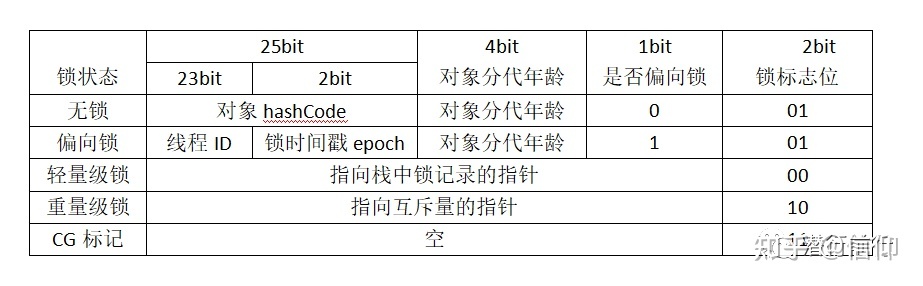
偏向锁:当只有一个线程访问锁对象时候,这时会在锁对象头标记当前锁为偏向锁,并记录当前占有锁的线程id;
轻量锁:当有少数的多个线程竞争同一个锁对象时,会把锁对象头标记为轻量级锁,轻量级锁底层会执行CAS操作,只有CAS成功的线程才能获得锁,其它的线程执行自旋操作,自旋到一定次数后会升级为重量级锁;
重量级锁:当有大量的线程竞争锁时,就会升级为重量级锁,此时没有获取到锁的线程都会进入_EntryList队列中进行排队,重量级锁会有线程的停止和运行,CPU的上下文切换,这些操作都是比较耗费时间的,因此重量级锁效率低。
既然重量级锁的效率低为啥还要使用呐?
如果只使用轻量级锁来处理大量线程,那么只能有一个线程获取锁去执行代码,而其它的线程都在自旋操作会迅速的耗尽CPU的资源,因此还是得使用重量级锁。
synchronized对锁的优化不仅仅是锁升级,还有:
锁粗化:在一个方法中多次加锁也是比较耗费性能的,如果在一个方法中多次加的锁是同一把锁,jvm会把它们合并为一个锁,这样就可以减少不必要的消耗;
public void test(){
synchronized(this){
System.out.println("hello");
}
synchronized(this){
System.out.println("world");
}
}合并为:
public void test(){
synchronized(this){
System.out.println("hello");
System.out.println("world");
}
}锁消除:对方法进行逃逸分析,如果方法里面的变量只在方法内使用,没有在被外部的其它地方引用,那么该变量就未发生逃逸,可以进行锁消除,减少没必要的加锁操作,提高代码性能;
public void testA() {
int i = 0;
synchronized (this) {
i++;
}
}会进行锁消除操作:
public void testA() {
int i = 0;
i++;
}2)Lock对象:
ReentrantLock是java代码层面实现的锁对象;要用java实现锁最重要的是要让线程运行的阻塞等待,java能让线程等待的几个方式:
1)wait()
该方法只能在synchronized方法或者synchronized代码块中使用,否则会报IllegalMonitorStateException异常;并且wait的线程会释放锁和cpu的执行权,只能被notify()或者notifyAll()唤醒;由于它只能配合synchronized使用,因此不适合用来做锁的等待。
2)Thread.sleep()
该方法必须指定睡眠时间,而且到时后就会自动唤醒,不会释放锁但是会释放cpu执行权,因此不适合用来做锁的等待。
3)while循环
while可以让线程自旋,并且设置条件,满足条件的线程允许跳出循环,一般配合CAS来做自旋锁,不会释放cpu执行权;
public class CASDemo {
//测试自旋锁
private AtomicReference<String> reference = new AtomicReference();
//加锁
public void lock() {
while (!reference.compareAndSet(null, Thread.currentThread().getName())) {
}
System.out.println(Thread.currentThread().getName() + ":得到锁");
}
//解锁
public void unlock() {
reference.compareAndSet(Thread.currentThread().getName(), null);
System.out.println(Thread.currentThread().getName() + ":释放锁");
}
}4)park()
使用LockSupport.park()来让线程等待,LockSupport.unpark(Thread)来唤醒线程,不会释放锁,会释放cpu执行权,适合来做锁的等待;
public class MyParkLock {
public void lock() {
System.out.println(Thread.currentThread().getName() + "加锁");
LockSupport.park();
}
public void unLock(Thread thread) {
LockSupport.unpark(thread);
System.out.println(thread.getName() + "释放锁");
}
public static void main(String[] args) {
MyParkLock lock = new MyParkLock();
Thread thread1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "开始执行");
lock.lock();
System.out.println(Thread.currentThread().getName() + "结束执行");
}, "thread1");
Thread thread2 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "执行");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unLock(thread1);
}, "thread2");
thread1.start();
thread2.start();
}
}公平锁:线程按照先来后到的顺序获取锁对象,如果锁已被其它线程占有需要排队等待,不允许插队,并发效率低;
非公平锁:线程随机竞争锁,允许插队,并发效率高。
ReentrantLock类java实现的锁对象,可重入锁,默认未非公平锁;
可重入锁:同一个锁被多次使用,如果一个线程获取到最外层的锁,那么会自动获取到里面的锁:
public class ReentrantLockDemo {
private int count = 1;
private Lock lock = new ReentrantLock();
public void testA() {
lock.lock();
testB();
lock.unlock();
}
public void testB() {
lock.lock();
lock.unlock();
}
}线程执行testA()获取到锁后,会自动的获取到testB()中的锁;
注意:获取到几次锁就要释放几次锁。
ReentrantLock的加锁解锁代码的源码分析:
//当我们调用ReentrantLock无参构造器时:
public ReentrantLock() {
//默认创建一个非公平同步对象
sync = new NonfairSync();
}
//传入true得到公平锁
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}Sync对象继承于AbstractQueuedSynchronizer:

ReentrantLock的lock()调用了Sync实例对象的lock():
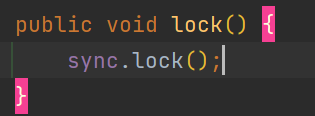
NonfairSync中的lock():


tryAcquire():

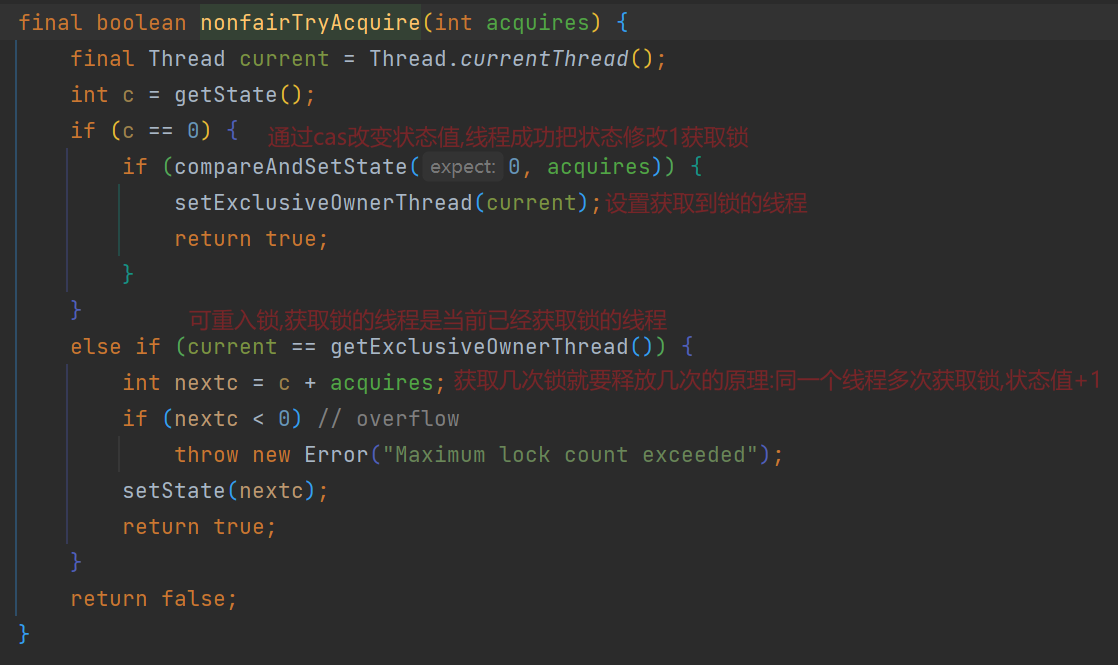
addWaiter()方法:
acquireQueued()方法:
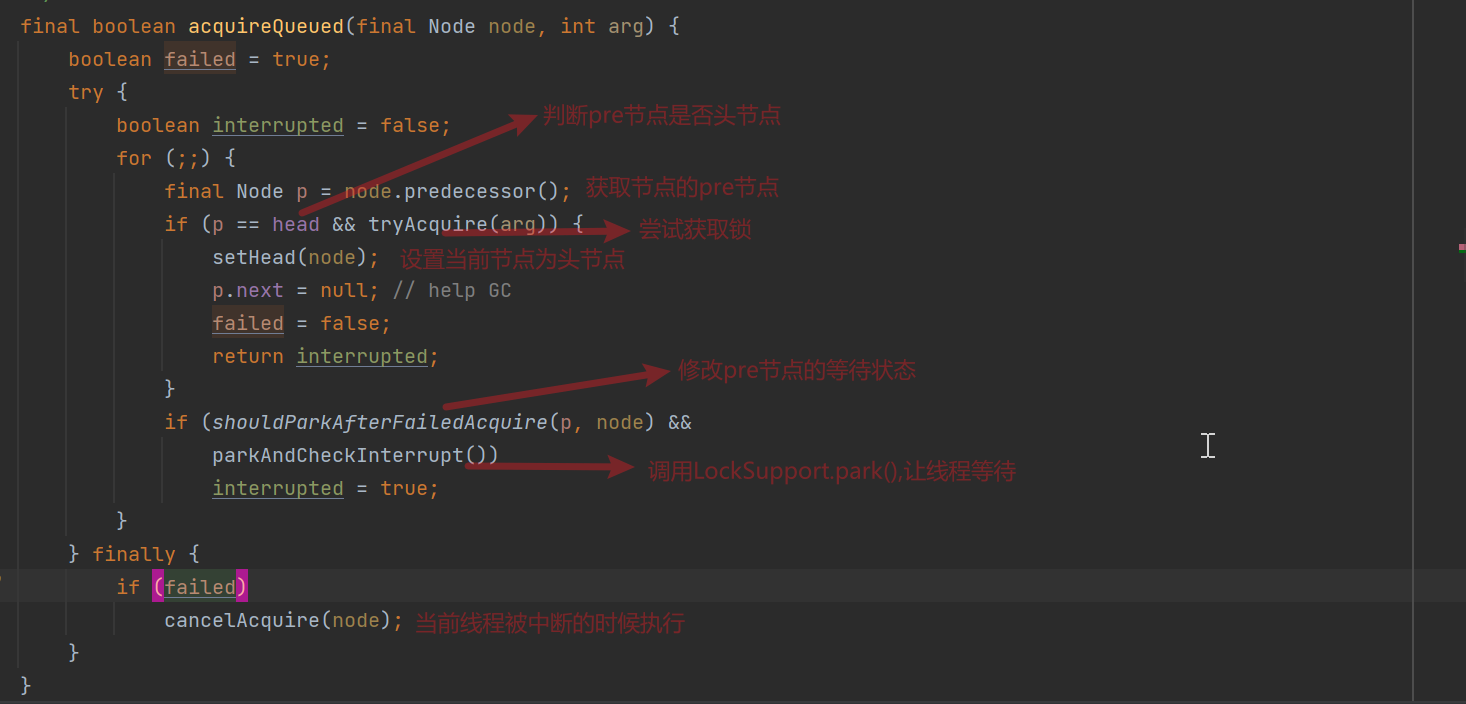
cancelAcquire()释放锁并且在链表中剔除当前线程被中断的当前节点;
FairSync中lock():
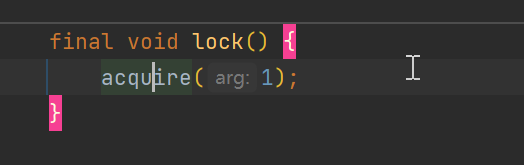
acquire():

tryAcquire():
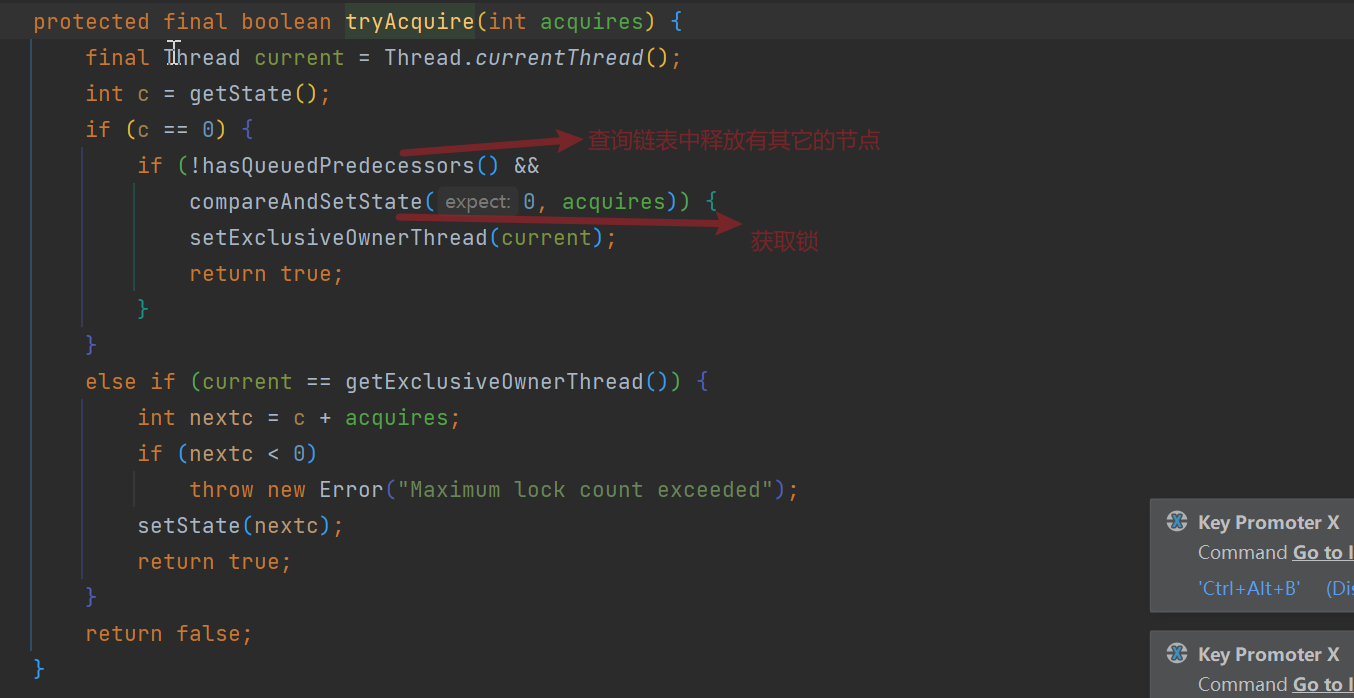
公平锁和非公平锁的区别:
公平锁:线程获取锁的时候先判断AQS链表有没有节点,如果没有则直接获取锁,否则排队获取;
非公平锁:现在先获取锁,获取锁失败则进入队列排队。
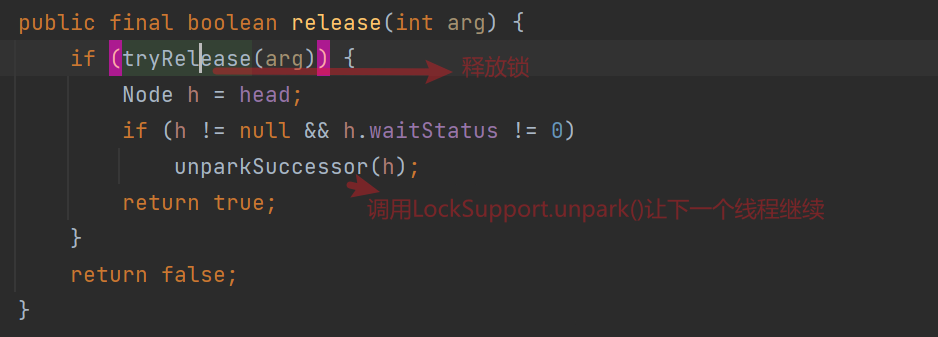
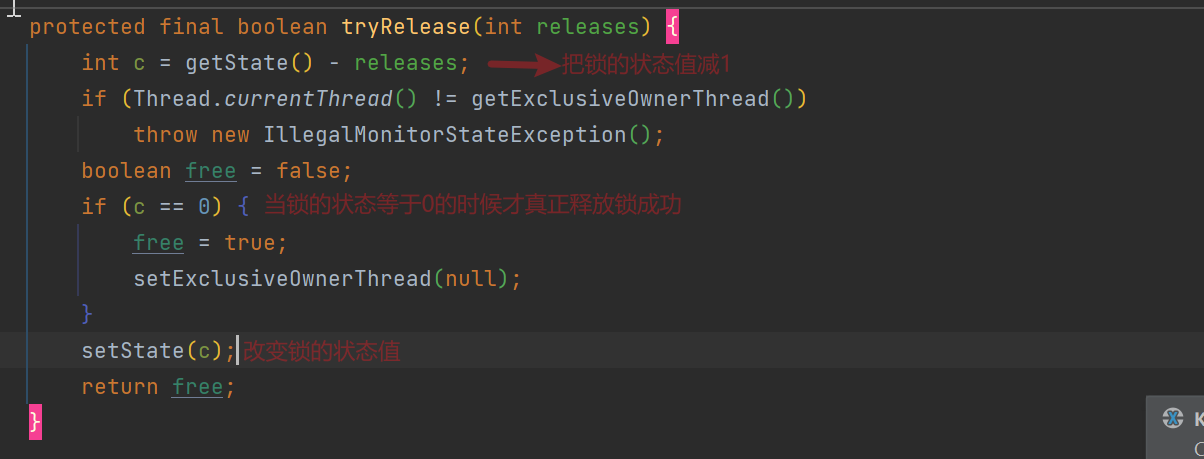
ReentrantLock的unlock():
4.CAS:
在使用ReentrantLock的时候经常看到compareAndSetState(old,new)方法,这个方法的作用是比较旧值如果匹配则把旧值修改为new值,这个操作是原子性的;
Unsafe 是位于 sun.misc 包下的一个类,Unsafe 提供了CAS 方法,直接通过native 方式(封装 C++代码)调用了底层的 CPU 指令 cmpxchg。
Unsafe unsafe = Unsafe.getUnsafe();
/*
@param o 包含要修改的字段的对象
@param offset 字段在对象内的偏移量
@param expected 期望值(旧的值)
@param update 更新值(新的值)
@return true 更新成功 | false 更新失败
*/
unsafe.compareAndSwapInt(obj, offset , expect, update);Unsafe 提供的获取字段(属性)偏移量的相关操作,主要如下:
/**
* @param o 需要操作属性的反射
* @return 属性的偏移量
*/
public native long staticFieldOffset(Field field);
public native long objectFieldOffset(Field field);CAS的典型运用:Atomic类
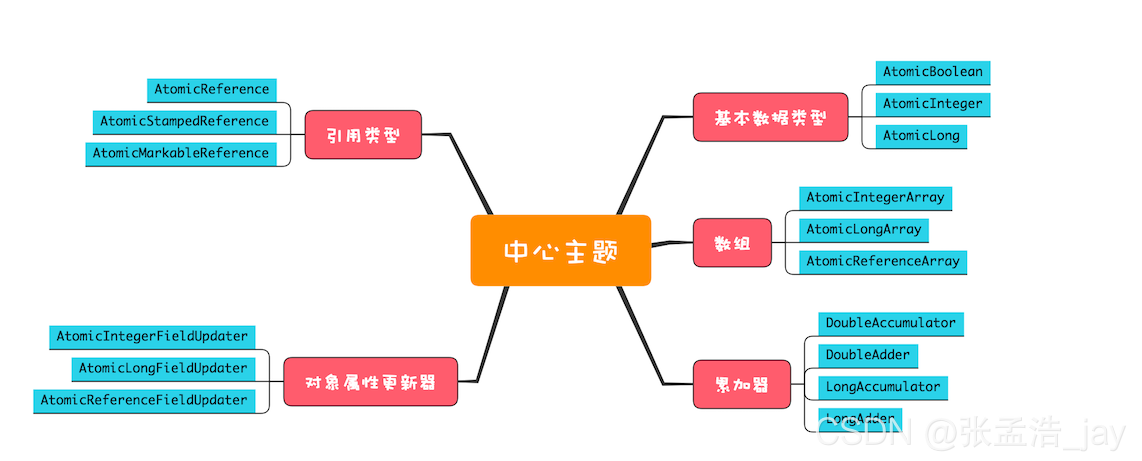
CAS的缺点:
1.ABA问题:
当A线程要把1->2,这时候B线程把1->3->1,线程A再执行的时候,B线程率先一步执行完成,这时候虽然A能把1->2,但是实际值是已经变化过的,但是我们的A线程不能感知到,这就是ABA问题;
JDK 提供了两个类 AtomicStampedReference、AtomicMarkableReference 来解决 ABA 问题。
2.只能保证一个共享变量的原子操作:
JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,可以把多个变量放在一个 AtomicReference 实例后再进行 CAS 操作;
3. 循环时间长开销大:
高并发下N多线程同时去操作一个变量,会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。
解决 CAS 恶性空自旋的较为常见的方案为:
- 分散操作热点,使用 LongAdder 替代基础原子类 AtomicLong。
- 使用队列削峰,将发生 CAS 争用的线程加入一个队列中排队,降低 CAS 争用的激烈程度。JUC 中非常重要的基础类 AQS(抽象队列同步器)就是这么做的。
5.AQS:
AQS是AbstractQueuedSynchronizer的首字母缩写,AQS里面定义了一个Node类,Node里面有pre,next和Thread属性,实际就是一个双向链表,用Node承载线程对象,并且用LockSupport.park()方法让链表里面的线程等待,LockSupport.unpark(thread)让链表里面的线程依次唤醒。
为什么要有AQS?
如果使用自旋锁,在高并发的情况下CPU资源会被迅速用完,从而导致cpu百分百问题,为了解决这个问题引入AQS,让没有CAS成功的线程进入链表等待,从而达到解决cpu被占满的情况。
6.Volatile:
volatile是java中的一个关键字,作用是保证变量的内存可见性,禁止指令重排序
1)volatile用法:
直接在要被多线程访问的变量前添加:
public class VolatileDemo {
private volatile int num = 0;
}2)volatile的可见性:
当多个线程在访问同一个变量时,每个线程会把共享变量读取到自己独有的操作内存中进行操作,然后再把结果回写给主存,在这个过程中多个线程可能在同一时刻读到相同值进行操作,当一个线程改变了主存的值,其它线程操作的还是旧的值,从而导致并发安全问题,当操作的是volatile修饰的变量,一个线程改变了主存的值,JVM会向处理器发送一条lock前缀的指令,将这个缓存中的变量回写到系统主存中,会把每个线程读取到自己操作内存的值设置为无效,当线程要操作该值的时候发现无效状态,会强制重新从系统内存里重新读取变量值。
3)volatile的原子性:
原子性:一个操作要么全部成功,要么失败,在这个过程不会被其它因素打断;
public class VolatileDemo {
private volatile int num = 0;
public void add() {
num++;
}
public static void main(String[] args) throws InterruptedException {
VolatileDemo demo = new VolatileDemo();
for (int i = 0; i < 20; i++) {
new Thread(() -> {
for (int i1 = 0; i1 < 1000; i1++) {
demo.add();
}
}).start();
}
//正确结果应该是20000,实际往往小于20000
System.out.println(demo.num);
}
}num++并不是原子操作,它实际操作读取num->加1->写回num:
0 aload_0
1 dup
2 getfield #2 <org/test/juc/VolatileDemo.num : I> //获取num字段值
5 iconst_1 //入栈
6 iadd //执行添加操作
7 putfield #2 <org/test/juc/VolatileDemo.num : I> //把结果写回num
10 returnvolatile只能保证获取操作的值是最新的值,不能保证添加操作和回写操作的值是最新的。
4)volatile禁止指令重排序:
指令重排序:系统为了提高执行效率会把代码或者执行的步骤进行顺序的调整,前提是不能改变程序的执行结果。


JVM代码重排序:
public class VolatileDemo {
int a = 0, b = 0, c = 0, d = 0;
public void test() {
new Thread(() -> {
c = b;
a = 1;
}, "A").start();
new Thread(() -> {
d = a;
b = 1;
}, "B").start();
}
}
//我们的期望值c=0,a=1,d=1,b=1
//实际可能a=1,b=1,c=1,d=1或者a=1,b=1,c=0,d=0导致a,b,c,d的值与期望值不一样,是因为jvm对我们的代码进行了重排序,在单个线程中如果前后代码没有必然的联系,jvm可能会对代码进行重排序,因此在线程A中可能先执行a=1,再执行c=b,线程B中可能先执行b=1,d=a,原因是在他们单个线程中c和a,d和b没有必要联系;
JVM指令集重排序:
public class Lazy {
private static Lazy lazy = null;
/** 私有化构造器 */
private Lazy(){
}
public static Lazy getInstance(){
if (lazy == null) {
/**
10 monitorenter //监控器,添加锁
11 getstatic #2 <org/test/design/single/Lazy.lazy : Lorg/test/design/single/Lazy;>
14 ifnonnull 27 (+13)
17 new #3 <org/test/design/single/Lazy> //创建一个Lazy实例对象
20 dup
21 invokespecial #4 <org/test/design/single/Lazy.<init> : ()V> //调用Lazy的init方法
//把Lazy实例对象赋值给lazy属性
24 putstatic #2 <org/test/design/single/Lazy.lazy : Lorg/test/design/single/Lazy;>
27 aload_0
28 monitorexit
*/
synchronized (Lazy.class) {
if (lazy == null) {
lazy = new Lazy();
}
}
}
return lazy;
}
}在上面的单例模式中,由于操作lazy = new Lazy()操作是单个线程完成的,并且在字节码指令中invokespecial和putstatic操作并没有必然的依赖关系,当invokespecial和putstatic操作调整顺序结果也不会改变(满足as-if-serial),因此当某一个线程执行时先执行的putstatic,这时候就会把一个没有进行invokespecial操作的对象赋值给lazy 变量,此时其它的线程执行getInstance()会获取到一个没有执行init方法的不完整对象;
解决单例模式的双重检查指令重排问题: private volatile static Lazy lazy = null;
为什么volatile能够禁止指令重排?
当我们读或者修改被volatile修饰的变量时,jvm会在这个变量的前后加上内存屏障;
1、在每个volatile写操作的前面插入一个StoreStore屏障。
2、在每个volatile写操作的后面插入一个StoreLoad屏障。
3、在每个volatile读操作的后面插入一个LoadLoad屏障。
4、在每个volatile读操作的后面插入一个LoadStore屏障。
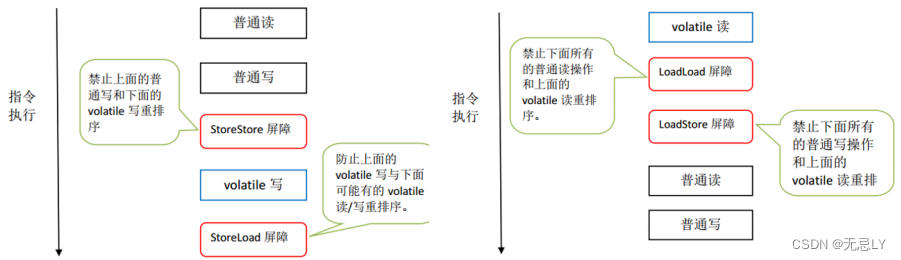
内存屏障的两个功能:
- 阻止屏障两边的指令重排序
- 刷新处理器缓存
volatile底层源码:
7.线程池:
在java中创建和销毁线程开销是很大的,需要给它分配内存、列入调度,同时在线程切换的时候还要执行内存换页,CPU 的缓存被清空,切换回来的时候还要重新从内存中读取信息,破坏了数据的局部性。【分配内存、列入调度、内存换页、清空缓存和重新读取】。
为了降低创建线程的开销,我们可以使用线程池来管理线程,线程池在创建时先会创建一些线程出来,用的时候直接从线程池里拿,用完还给线程池即可,复用线程池里面的线程,从而避免总是创建,销毁线程导致的开销过大。(空间换时间)
创建线程池:
//创建一个固定的线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
//创建一个单例线程池
ExecutorService executor = Executors.newSingleThreadExecutor();
//创建一个自适应大小的线程池
ExecutorService executor = Executors.newCachedThreadPool();阿里巴巴规范中禁止使用上面三种方式创建线程池,原因:
//单例线程池
ExecutorService executor = Executors.newSingleThreadExecutor();;
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
//创建队列LinkedBlockingQueue
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
//我们可以看到队列容量最大是Integer.MAX_VALUE,如果在高并发的情况下队列很容易存储大量的对象,从而导致OOM//固定线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
//我们可以看到队列容量最大是Integer.MAX_VALUE,如果在高并发的情况下队列很容易存储大量的对象,从而导致OOM//自适应线程池
ExecutorService executor = Executors.newCachedThreadPool();
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
//我们可以看到最大线程数是Integer.MAX_VALUE,如果高并发会创建大量的线程,导致CPU资源被迅速耗尽手动创建线程池:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
3, //核心线程数
5, //最大线程数
1L, //非核心线程存活时间
TimeUnit.SECONDS, //时间单位
new ArrayBlockingQueue<>(3), //线程阻塞队列
Executors.defaultThreadFactory(), //线程工厂
//new ThreadPoolExecutor.AbortPolicy(), //如果线程数超出了线程池最大的容量,爆出异常
//new ThreadPoolExecutor.CallerRunsPolicy() //如果线程数超出了线程池最大的容量,那个线程启动的线程池,那个线程执行
//new ThreadPoolExecutor.DiscardPolicy() //如果线程数超出了线程池最大的容量,丢弃任务,不抛出异常
new ThreadPoolExecutor.DiscardOldestPolicy() //如果线程数超出了线程池最大的容量,丢弃队列中旧的任务
);
//使用线程池
for (int i = 0; i < 9; i++) {
executor.execute(() -> { //每调用一次这个方法,相当于启动一个线程
System.out.println(Thread.currentThread().getName() + "执行");
});
}
//关闭线程池
executor.shutdown();
