Elasticsearch
1.什么是Elasticsearch:

2.为什么要使用Elasticsearch:

3.es和solr的区别:


4.倒排索引是什么:

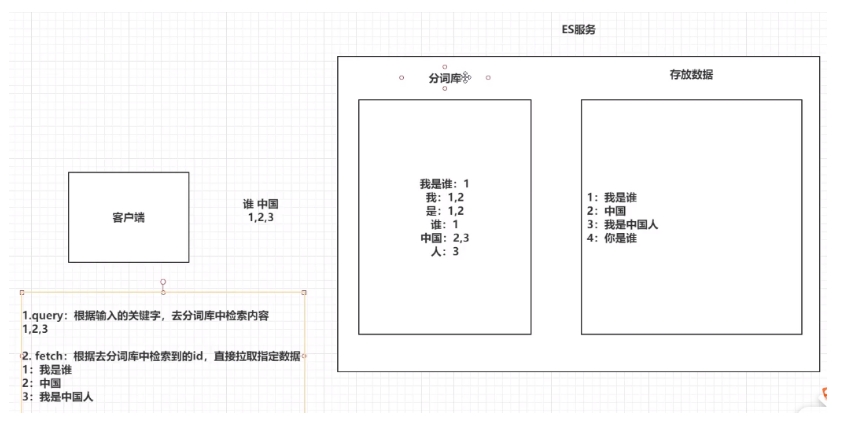
5.安装es+kibana:
使用docker安装es:
1.获取es镜像
docker pull elasticsearch:7.2.02.启动es
docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e “ES_JAVA_OPTS=-Xms512m -Xmx512m” --name=es --net=elasticsearch3.修改配置解决跨域问题
#进入到容器内部
docker exec -it es /bin/bash
#修改配置文件
vi /config/elasticsearch.yml
#追加内容
http.cors.enabled: true #允许跨域
http.cors.allow-origin: "*" #允许所有请求跨域
#退出容器
exit
#重启容器
docker restart es4.如果通过ip:9200访问es服务配置:
http.host: 0.0.0.0
#es默认是以localhost:9200访问服务5.测试安装成功:
安装Elasticsearch-head:
Elasticsearch-head是一款可视化Elasticsearch插件;安装这个直接使用谷歌插件即可。
安装ik分词器:
#进入容器内部
docker exec -it es /bin/bash
#进入到插件目录
cd /plugins
#安装插件
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip
#退出容器
exit
#重启容器
docker restart es安装kibana
kibana用来操作elasticsearch的一款可视化平台软件。
1.获取镜像
docker pull kibana:7.2.0 #注意:版本号一定要与elasticsearch版本号一致2.启动kibana
docker run --name kibana --link=elasticsearch:test -p 5601:5601 -d kibana:7.2.03.Kibana在6.7以后的版本,支持了多种语言。并且自带在安装包里。修改方式如下:
#进入到kibana里面
docker exec -it kibana
#修改配置
vi /config/kibana.yml
#增加配置
i18n.locale: "zh-CN"
#重启容器4.如果要使用ip:5601的方式访问
#修改kibana.yml
server.host: "192.168.2.102"5.如果访问不到es:
elasticsearch.hosts: ["http://192.168.2.102:9200"]6.访问页面:
6.es结构
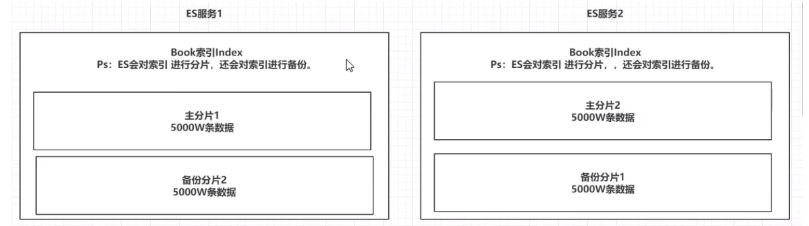
1.索引indices(类似mysql的库)
es服务可以创建多个索引;
每一个索引默认被分为5片储存,每一个分片都会存在至少一个备份分片;
备份分片一般不会帮助检查数据,但是当es索引的查询压力特别大的时候,备份分片才会帮助检查数据;
备份分片必须放在不同的es服务中。
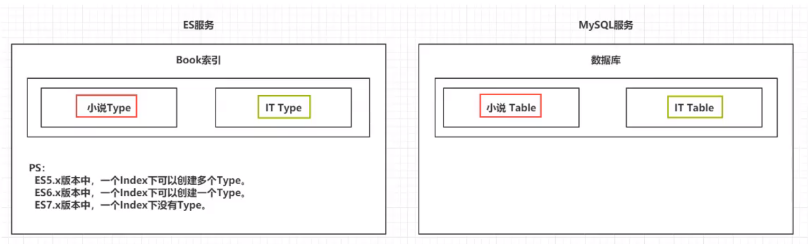
2.类型types(类似mysql中的表)
一个索引下,可以创建对个类型;
根据版本不同,创建的类型也不同。
es5.x版本,一个index下可以有多个type;
es6.x版本,一个index下可以创建一个type;
es7.x版本,一个index下没有type。
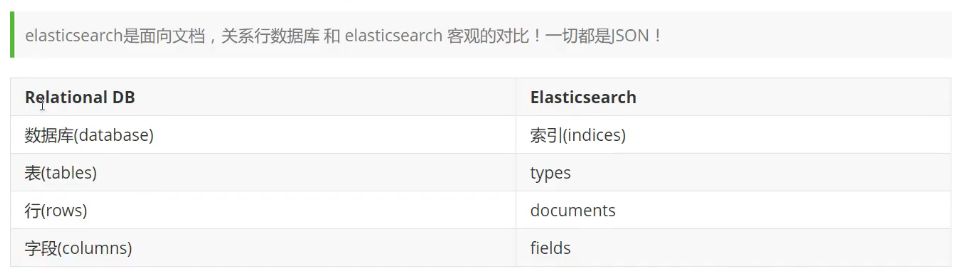
3.文档documents(类型mysql中的一条数据)
一个类型下可以有多个文档,这个文档类似于mysql中的多行数据。

4.字段fields(类似mysql中表的列)
一个文档中可以包含多个字段,类似mysql表中的列。

总结:
7.ik分词器操作方法:
1.ik分词器的分词方式:
ik_max_word:
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart :
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
2.使用方式:
ik_max_word:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是大神仙"
}
################### 结果 #######################
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "大神",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "神仙",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
}
]
}ik_smart:
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是大神仙"
}
############# 结果 ###################
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "大",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "神仙",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
}
]
}3.自定义ik词典:
ik分词器,分词都是根据词典(ik的config目录中各种xxxx.dic就是词典)来分的,如果我们需要拓展分词,则可以自定义词典。
1.编写自定义词典:
#编写一个xlw.dic的词典
内容为:肖龙威2.启用自定义词典:
修改ik的config目录的IKAnalyzer.cfg.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">xlw.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>3.测试是否成功:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是肖龙威"
}
################### 结果 #####################
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "肖龙威",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
8.操作es的RESTFUL语法
GET请求用来获取数据
#查看索引信息
#以postman的方式访问
http://ip:9200/index
#以kibana的方式访问
GET /index
#查看文档信息
GET /index/type/doc_id #注意es7版本后没有类型POST请求用来更新数据
POST /index/type/_search #查询文档,可以通过json来指定查询条件
POST /index/type/doc_id/_update #修改文档,修改内容写在json里PUT请求用来创建索引
PUT /index #创建索引,可以通过json配置索引,还可以指定字段DELETE请求用来删除索引和数据
DELETE /index #删除索引,会删除所有文档
DELETE /index/type/doc_id #删除指定的文档9.Filed类型
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.2/mapping-types.html
字符串类型
text:被用于全文检索,将当前的filed进行分词。
keyword:关键字,当前filed不会被分词。
数值类型
byte
short
integer
long
float
half_float:精度比float小一半
double
时间类型
date
布尔类型
boolean
二进制类型
binary:支持base64编码的string
范围类型
integer_range:赋值时无需指定具体的内容,只需储存一个范围即可,如gt、lt、gte、lte
long_range
double_range
float_range
date_range
经纬度类型
geo_point:用来储存经纬度
ip类型
ip
10.操作es
1.创建索引(不带字段)
#创建一个名为book的索引
PUT /book
{
#对索引进行设置
"settings": {
#索引分片数为5个
"number_of_shards": 5,
#索引每个分片的备份数为1个
"number_of_replicas": 1
}
}
################ 结果 ######################
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "book"
}
2.创建一个带字段的索引
PUT /persion
{
#设置索引
"settings": {
#索引切片数2个
"number_of_shards": 2,
#索引切片的备份数
"number_of_replicas": 1
},
#指定索引数据的结构
"mappings": {
#指定文档的filed
"properties": {
#filed名称
"name": {
#filed的类型
"type": "keyword",
#filed是否能当做索引的条件
"index": true,
#是否需要额外储存
"store": false
},
"age": {
"type": "integer"
},
"birth": {
"type": "date",
#指定日期类型的格式化方式
"format": ["yyyy/MM/dd HH/mm/ss"]
},
"describe": {
"type": "text",
"index": true,
"store": false,
#指定分词器为ik分词器
"analyzer": "ik_max_word"
}
}
}
}
################## 结果 #######################
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "persion"
}
为索引添加新字段: post index_name/_mapping方式即可
改变索引字段类型: 重建索引
3.添加一个文档
在es中唯一的标识_index(表示那个索引)、_type(表示那个类型,es5版本可以有多个类型;es6版本只能有一个类型,首选类型名称是 _doc;es7版本中没有类型,在7.0中,它_doc是路径的永久部分,代表端点名称而不是文档类型)、_id(表示文档ID),通过这三个字段来锁定一组文档。
指定文档id
#put /index/type/doc_id 指定文档id的方式提交
PUT /persion/_doc/1
{
"name": "小白白",
"age": "15",
"birth": "1995/04/17 12/30/00",
"describe": "我是小白白啊,大家好"
}
############# 结果 #########################
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 2
}

_index:那个索引;
_type:那个类型;
_id:文档id;
#也可以通过 post /index/type/doc_id 的方式创建指定文档id
POST /persion/_doc/3
{
"name": "柯莉堃",
"age": "16",
"birth": "1995/04/17 12/30/00",
"describe": "大叔大婶,大家好"
}
############# 结果 ################
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}

不指定文档id
POST /persion/_doc
{
"name": "小嘿嘿",
"age": "15",
"birth": "1995/04/17 12/30/00",
"describe": "我是小嘿嘿啊,大家好"
}
################ 结果 #########################
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "e__skHcBQnrHOuXw1gwm",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 2
}
不指定id用post方式提交,es服务会随机分配一个id号。
批量添加
POST _bulk
{"create" : {"_index" : "class", "_id" : 4}}
{"name" : "一班", "stu_count" : 10, "code" : "0004"}
{"index" : {"_index" : "class", "_id" : 5}}
{"create" : "二班", "stu_count" : 10, "code" : "0005"}
//create:如果文档不存在就创建,但如果文档存在就返回错误
//index 如果文档不存在就创建,如果文档存在就更新
//某一个操作失败,是不会影响其他文档的操作的,它会在返回结果中告诉你失败的详细的原因。4.修改文档
覆盖修改
#覆盖修改需要指定每一个字段的值,不然就会被覆盖成null
PUT /persion/_doc/1
{
"name": "大白",
"age":"25",
"birth": "2000/01/30 00/30/00",
"describe": "呵呵呵呵"
}不覆盖修改
#改指定字段,其它字段的值不会置为null
POST /persion/_doc/1/_update
{
"doc":{
"name": "大子白"
}
}
######### 结果 ################################
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 8,
"_primary_term" : 2
}批量修改:
POST _bulk
{"update" : {"_index" : "hello","_id" : "1"}}
{"doc" : {"age" : 8}}
{"update" : {"_index" : "hello","_id" : "2"}}
{"doc" : {"age" : 4}}5.删除操作
#DELETE /index/type/doc_id 删除文档
DELETE /persion/_doc/e__skHcBQnrHOuXw1gwm
#删除索引
DELETE /index批量删除
POST _bulk
{"delete" : {"_index" : "class", "_id" : 4}}
{"delete" : {"_index" : "class", "_id" : 5}}6.查询操作
1.term查询
term查询:代表完全匹配,不会对查询的关键字进行分词,而是直接把查询的关键字拿到分词字典中去匹配,并返回匹配到的对应的文档。
GET /persion/_doc/_search
{
"from": 0, #类似mysql中的limit ?,从那条文档开始返回
"size": 3, #类似mysql中的limit ?,* ,返回多少条文档
"query":{
"term":{
#查询的filed : value
"name": "小子"
}
}
}
############### 结果 ##########################
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.5753642,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "臭小子在干吗啊"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 0.5753642,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "大萨达撒是"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 0.5753642,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "爱生气翁群翁无群"
}
}
]
}
}2.terms查询
terms查询:terms跟term查询机制是一样的,都不会将查询关键字进行分词,而是直接去分词字典中匹配,并将匹配的相关文档返回。
term跟terms的区别:
1.term只能根据一个字段的一个值查询一条文档,类似sql的 where id=1;
2.terms可以根据一个字段的多个值查询多条文档,类似sql的 where id=1 or id=2 ...。GET /persion/_search
{
"from":0,
"size": 3,
"query": {
"terms": {
"name": [
"大子白",
"科学家",
"小花花"
]
}
}
}
###################### 结果 #########################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "科学家"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "小花花",
"age" : "16",
"birth" : "1995/04/17 12/30/00",
"describe" : "我是小花花啊,大家好"
}
}
]
}
}3.match_all查询
match_all查询:匹配所有的文档。
GET /persion/_search
{
"query": {
"match_all": {}
}
}
################# 结果 ####################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "科学家"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "小花花",
"age" : "16",
"birth" : "1995/04/17 12/30/00",
"describe" : "我是小花花啊,大家好"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "臭小子在干吗啊"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "大萨达撒是"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "爱生气翁群翁无群"
}
}
]
}
}4.match查询
match查询:match查询属于高层查询,它会将你查询的字段类型不同,而采取不同的查询方式。
1.查询的如果是日期字段或者数值字段,它会将你的查询字符串转化为对应的日期或者数值;
2.如果查询的是一个不能分词的keyword字段,match查询不会对你的查询关键字进行分词;
3.如果查询的是一个可以被分词的text字段,match会将你查询的关键字进行分词,去分词库中匹配指定的值,并将对应 值的文档返回。
4.match查询的底层实际是多个term查询,将多个term查询的结果封装到一起。根据一个字段包含单个关键字查询
GET /persion/_search
{
"query": {
"match": {
"name": "大子白"
}
}
}
############ 结果 ################
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.6739764,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.6739764,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
}
]
}
}
根据一个字段包含多个关键字查询
根据一个字段的值包含多个查询关键字,采用and或者or的方式连接。
GET /persion/_search
{
"query": {
"match": {
#filed
"describe": {
#查询的内容
"query": "呵呵 大",
"operator": "or" #包含呵呵or大
}
}
}
}
############ 结果 #############
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.6921797,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 2.6921797,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.6183326,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "大萨达撒是"
}
}
]
}
}GET /persion/_search
{
"query": {
"match": {
"describe": {
"query": "爱 生气",
"operator": "and" #字段值包含爱and生气
}
}
}
}
################## 结果 ###########################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 3.179408,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 3.179408,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "我爱这个生气"
}
}
]
}
}
5.mulit_match查询
match是针对一个filed做索引,mulit_match是针对多个filed进行索引,多个filed对应着一个查询关键字。
GET /persion/_search
{
"query": {
"multi_match": {
"query": "呵呵",
"fields": ["name","describe"] #字段name或者describe包含 呵呵 都查询出来
}
}
}
############### 结果 ###################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 3.1003478,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 3.1003478,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "9",
"_score" : 1.89712,
"_source" : {
"name" : "呵呵",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "我是小子白"
}
}
]
}
}6.id查询
id查询就是根据文档的id进行查询,类似sql的 where id=?
GET /persion/_doc/1 #查询索引persion中id为1的文档,这里的_doc不是类型名,而是es7版本的固定写法
############# 结果 ###############
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"_seq_no" : 8,
"_primary_term" : 2,
"found" : true,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
}
7.ids查询
ids查询:根据多个id查询,类型sql的where id in (1,2,3)。
GET /persion/_search
{
"query": {
"ids": {
#指定多个文档id
"values": [1,2,3]
}
}
}
############ 结果 #############
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "科学家"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "小花花",
"age" : "16",
"birth" : "1995/04/17 12/30/00",
"describe" : "我是小花花啊,大家好"
}
}
]
}
}8.prefix查询
prefix查询,通过一个关键字去匹配一个字段内容的前缀,从而查询到指定的文档。
GET /persion/_search
{
"query": {
"prefix": {
"name": {
"value": "小" #查询name字段内容以小开头的文档
}
}
}
}
############### 结果 ##############
{
"took" : 14,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "小花花",
"age" : "16",
"birth" : "1995/04/17 12/30/00",
"describe" : "我是小花花啊,大家好"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "臭小子在干吗啊"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "爱生气翁群翁无群"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "我爱这个生气"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "8",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "爱好把生气"
}
}
]
}
}9.fuzzy查询
fuzzy查询,模糊查询就是我们输入一个大概关键字,es就会通过大概关键字,匹配大概的结果,从而达到搜索有错别字的情形。
GET /persion/_search
{
"query": {
#模糊查询
"fuzzy": {
#字段
"name": {
"value": "大子百", #查询关键字
"prefix_length": 2, #前两个字符不能被模糊查询
"fuzziness": "auto" #模糊性,它可以被设置为“0”, “1”, “2”或“auto”,推荐"auto"
}
}
}
}
################ 结果 ################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2647465,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.2647465,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
}
]
}
}10.wildcard查询
wildcard查询:通配符查询,跟mysql中的like查询相似,在查询关键字中指定通配符*或者占位符?。
GET /persion/_search
{
"query": {
"wildcard": {
"name": {
"value": "小*" #查询name内容以"小"开头的所有文档
}
}
}
}
################ 结果 ##################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "小花花",
"age" : "16",
"birth" : "1995/04/17 12/30/00",
"describe" : "我是小花花啊,大家好"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "臭小子在干吗啊"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "爱生气翁群翁无群"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "我爱这个生气"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "8",
"_score" : 1.0,
"_source" : {
"name" : "小子",
"age" : 5,
"birth" : "2000/02/02 12/30/30",
"describe" : "爱好把生气"
}
}
]
}
}
11.range查询
range查询:范围查询,只针对数值类型,对某一个数值字段进行大于或者小于的范围指定。
GET /persion/_search
{
"query": {
"range": {
"age": {
"gte": 15, #大于等于15
"lte": 25 #小于等于25
#gt:大于 gte:大于等于 eq:等于 lte:小于等于 lt:小于
}
}
}
}
############### 结果 ###############
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "大子白",
"age" : "25",
"birth" : "2000/01/30 00/30/00",
"describe" : "呵呵呵呵"
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "小花花",
"age" : "16",
"birth" : "1995/04/17 12/30/00",
"describe" : "我是小花花啊,大家好"
}
}
]
}
}12.regexp查询
regexp查询:正则查询,通过正则表达式去查询内容。
prefix、fuzzy、wildcard和regexp查询速率相对较低,如果要求速率比较高,应该避免去使用。
GET /book/_search
{
"query": {
"regexp": {
"NO": "12[0-9]{4}" #正则表达式只能作用在字符串类型的字段上
}
}
}
############## 结果 ###########################
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "射雕英雄传",
"NO" : "123456"
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "天龙八部",
"NO" : "123451"
}
}
]
}
}13.scroll查询
from&size和scroll&size的区别:
1.from&size是有限制的,from和size二者之和的数据不能超过1w条;
2.from&size的原理:
1).将用户查询的关键词进行分词;
2).将词汇拿到分词库中进行检索,得到多个文档的id;
3).根据文档id去各个分片获取指定的文档,这一步比较耗时;
4).将获取到的数据根据_score进行排序,耗时较长;
5).根据from的值将获取到的文档舍去一部分;
6).根据size的值返回对应条数数据。
3.scroll&size的原理:
1).将用户查询的关键词进行分词;
2).将词汇拿到分词库中进行检索,得到多个文档的id;
3).将文档id存放在一个es上下文中;
4).根据size(相当于一个指针)的数值去es上下文中检索指定个数文档,如果es上下文中的id被拿完,则es上下文会被删除;
5).如果需要下一页数据,直接去es上下文中继续根据size检索文档。
4.scroll查询,不适合做实时查询。
5.from&size会造成数据的浪费;
7.scroll的性能比from好。
8.scroll相当于一次性把所有满足查询条件的数据全部缓存,需要的时候根据缓存id去取.第一次查询
#第一次查询,会得到首页并且把文档ID信息存放到es上下文中,和scroll_id
#scroll=5m es上下文的保存时间为5分钟,如果时间到了则es上下文会自动被删除
GET /persion/_search?scroll=5m
{
"size": 3, #返回3条数据
"query": {
"match_all": {} #查询方式匹配所有
},
"sort": [ #指定排序
{
"age": {
"order": "asc" #按照年龄升序排序
}
}
]
}
################## 结果 ##################
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAGugWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZxZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAGukWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZw==",
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : null,
"_source" : {
"name" : "上官婉儿",
"age" : 18,
"birth" : "2002/02/02",
"describe" : "我不是一个法师",
"phone" : 15174692184
},
"sort" : [
18
]
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "柯莉堃",
"age" : 24,
"birth" : "1997/04/17",
"describe" : "我是柯莉堃啊",
"phone" : 18946297416
},
"sort" : [
24
]
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "肖战",
"age" : 25,
"birth" : "1996/03/15",
"describe" : "招黑体质",
"phone" : 13594462687
},
"sort" : [
25
]
}
]
}
}
继续查询(下一页)
#下一页,查询下一页是直接根据es上下文中继续找,所以不需要指定索引
GET /_search/scroll
{
#指定scroll_id,根据这个es上下文,继续查找
"scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAGugWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZxZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAGukWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZw==",
#指定es上下文的保存时间为1分钟
"scroll":"1m"
}
################## 结果 ###################
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAG1IWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZxZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAG1MWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZw==",
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "4",
"_score" : null,
"_source" : {
"name" : "关菲菲",
"age" : 50,
"birth" : "1981/05/18",
"describe" : "王者荣耀策划师",
"phone" : 13517946268
},
"sort" : [
50
]
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : null,
"_source" : {
"name" : "王宝强",
"age" : 55,
"birth" : "1979/05/18",
"describe" : "无敌绿巨人",
"phone" : 18849532476
},
"sort" : [
55
]
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "刘德华",
"age" : 60,
"birth" : "1973/01/12",
"describe" : "天王华仔",
"phone" : 15179461347
},
"sort" : [
60
]
}
]
}
}手动删除es上下文
#DELETE /_search/scroll/scroll_id 删除指定的es上下文
DELETE /_search/scroll/FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAGQEWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZxZnemVBbVluNVJxdU9NbVAybngxei13AAAAAAAAGQIWYlVDYUtJbG9SRHFBWFBaV3Q1MFhsZw==
#删除所有的es上下文
DELETE _search/scroll/_all14._delete_by_query查询删除
_delete_by_query查询删除:根据term、match等查询的方式删除大量的文档。
ps:如果你要删除的内容是index下的大部分数据,推荐创建一个全新的索引,将保留的文档内容放到新索引中。
POST /book/_delete_by_query
{
"query":{
"range":{
"NO":{
"gt":0 #把编号大于0的都删除
}
}
}
}
15._update_by_query查询修改
_update_by_query: 根据索引的查询操作,并配合script脚本,一次性修改大量文档.
POST hello/_update_by_query
{
"query" : {
"term" : {
"name" : "哆啦A梦"
}
},
"script": {
"lang": "painless",
"source": "ctx._source.count = params.count",
"params": {"count" : 500}
}
}16.bool查询
bool查询:复合过滤器,将多个查询条件,以一定的逻辑组合到一起。
must:所有的条件都必须满足,并且参与计算分值,类似sql的and;
should:所有的条件都可以满足,类似sql的or;
must_not:所有的条件都不能满足,类似sql的not;
filter:返回的文档必须满足filter子句的条件。但是不会像Must一样,参与计算分值。
GET /persion/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": {
"value": "柯莉堃"
}
}
},
{
"term": {
"name": {
"value": "刘德华"
}
}
},
{
"term": {
"name": {
"value": "肖战"
}
}
}
], #会把"柯莉堃"或者"刘德华"或者"肖战"的文档取出来
"must": [
{
"range": {
"age": {
"gt": 20,
"lt": 60
}
}
}
], #会把20<age<60的文档取出来
"must_not": [
{
"match": {
"describe": "体质"
}
}
], #会把describe字段中包含"体质"的文档去除
"filter": [
{
"term": {
"name": "柯莉堃"
}
}
] #过滤掉name不是"柯莉堃"的所有文档
}
}
}17.boosting查询
bootsting查询:可以帮助我们去影响查询后的score。
positive:只有匹配上positive的查询内容,才会被放到返回的结果集中;
negative:如果匹配上positive并且也匹配上negative,就可以降低文档的score;
negative_boost:指定系数,必须小于1.0;score = negative_boost*score。
关于查询时,分数如何计算:
1.查询的关键字在文档中出现的频次越高,分数也就越高;
2.指定的文档内容越短,分数越高;
3.我搜索的关键字会被分词,这个被分词的内容,被分词库匹配的个数越多,分数越高。
GET /persion/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"describe": "不是" #describe中包含"不是"的文档返回
}
},
"negative": {
"term": {
"name": {
"value": "关羽" #如果查询的文档字段name的内容是"关羽"的降低score
}
}
},
"negative_boost": 0.5 #降低score的指数是0.5
}
}
}
################## 结果 ##################
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.88964105,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 0.88964105,
"_source" : {
"name" : "上官婉儿",
"age" : 18,
"birth" : "2002/02/02",
"describe" : "我不是一个法师",
"phone" : 15174692184
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 0.4843276,
"_source" : {
"name" : "关羽",
"age" : 65,
"birth" : "1961/04/04",
"describe" : "我不是历史的关羽",
"phone" : 13579642589
}
}
]
}
}18.高亮查询
高亮查询,就是将你查询的关键字,以高亮的形式展示给客户端。
es提供了一个highlight属性,跟query同级,highlight属性还包含一些子属性:
fragment_size:指定高亮数据展示多少个字符回来;
pre_tags:指定前缀标签,如
post_tags:指定后缀标签,如;
fields:指定哪些字段以高亮的形式返回。
GET /persion/_search
{
"query": {
"match": {
"describe": "无敌"
}
},
"highlight": {
"fields": {
"describe": {}
},
"fragment_size": 10,
"pre_tags": "<front color='red'>",
"post_tags": "</front>"
}
}
########### 结果 ###########
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.7622693,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.7622693,
"_source" : {
"name" : "王宝强",
"age" : 55,
"birth" : "1979/05/18",
"describe" : "无敌绿巨人",
"phone" : 18849532476
},
"highlight" : {
"describe" : [
"<front color='red'>无敌</front>绿巨人"
]
}
}
]
}
}
19.聚合查询
es聚合查询和sql的聚合查询类似,但是es聚合查询比sql聚合查询功能钢架强大。
语法:
GET /index/_search
{
#指定聚合查询
"aggs":{
#自定义聚合查询的名称
"name":{
#指定聚合查询的查询类型
"agg_type":{
#指定需要查询的字段
"field":value
}
}
}
}去重计数查询:
去重计数,cardinality,第一步先将返回文档中的一个指定的field进行去重,然后统计一共有多少条文档。
GET /persion/_search
{
"aggs": {
#为这个聚合查询起名为agg
"agg": {
#指定聚合类型为去重统计
"cardinality": {
#去重字段为"name"
"field": "name"
}
}
}
}
############# 结果 #############
{
"took" : 996,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 24,
"birth" : "1997/04/17",
"describe" : "我是柯莉堃啊",
"phone" : 18946297416
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "刘德华",
"age" : 60,
"birth" : "1973/01/12",
"describe" : "天王华仔",
"phone" : 15179461347
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "肖战",
"age" : 25,
"birth" : "1996/03/15",
"describe" : "招黑体质",
"phone" : 13594462687
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "王宝强",
"age" : 55,
"birth" : "1979/05/18",
"describe" : "无敌绿巨人",
"phone" : 18849532476
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "上官婉儿",
"age" : 18,
"birth" : "2002/02/02",
"describe" : "我不是一个法师",
"phone" : 15174692184
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "关羽",
"age" : 65,
"birth" : "1961/04/04",
"describe" : "我不是历史的关羽",
"phone" : 13579642589
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "关菲菲",
"age" : 50,
"birth" : "1981/05/18",
"describe" : "王者荣耀策划师",
"phone" : 13517946268
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "8",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 12,
"birth" : "2008/04/05",
"describe" : "我也叫柯莉堃",
"phone" : 18115974684
}
}
]
},
"aggregations" : {
"agg" : {
"value" : 7
}
}
}
统计某字段的个数
相同字段的内容,也分开计数
GET /persion/_search
{
"aggs": {
"agg": {
"value_count": {
"field": "name"
}
}
}
}
############ 结果 #############
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 24,
"birth" : "1997/04/17",
"describe" : "我是柯莉堃啊",
"phone" : 18946297416
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "刘德华",
"age" : 60,
"birth" : "1973/01/12",
"describe" : "天王华仔",
"phone" : 15179461347
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "肖战",
"age" : 25,
"birth" : "1996/03/15",
"describe" : "招黑体质",
"phone" : 13594462687
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "王宝强",
"age" : 55,
"birth" : "1979/05/18",
"describe" : "无敌绿巨人",
"phone" : 18849532476
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "上官婉儿",
"age" : 18,
"birth" : "2002/02/02",
"describe" : "我不是一个法师",
"phone" : 15174692184
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "关羽",
"age" : 65,
"birth" : "1961/04/04",
"describe" : "我不是历史的关羽",
"phone" : 13579642589
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "关菲菲",
"age" : 50,
"birth" : "1981/05/18",
"describe" : "王者荣耀策划师",
"phone" : 13517946268
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "8",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 12,
"birth" : "2008/04/05",
"describe" : "我也叫柯莉堃",
"phone" : 18115974684
}
}
]
},
"aggregations" : {
"agg" : {
"value" : 8
}
}
}累加
把数值类型的数加起来。
GET /persion/_search
{
"aggs": {
"agg": {
"sum": {
"field": "age"
}
}
}
}
########## 结果 ##########
"aggregations" : {
"agg" : {
"value" : 309.0
}
}分组统计:
根据字段内容的相同,来统计个数。
GET /persion/_search
{
"aggs": {
"group": {
"terms": {
"field": "name",
"order": {
"_count": "desc" #输出结果根据统计个数排序
}
}
}
}
}
############ 结果 ##############
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 24,
"birth" : "1997/04/17",
"describe" : "我是柯莉堃啊",
"phone" : 18946297416
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "刘德华",
"age" : 60,
"birth" : "1973/01/12",
"describe" : "天王华仔",
"phone" : 15179461347
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "肖战",
"age" : 25,
"birth" : "1996/03/15",
"describe" : "招黑体质",
"phone" : 13594462687
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "王宝强",
"age" : 55,
"birth" : "1979/05/18",
"describe" : "无敌绿巨人",
"phone" : 18849532476
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "上官婉儿",
"age" : 18,
"birth" : "2002/02/02",
"describe" : "我不是一个法师",
"phone" : 15174692184
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "关羽",
"age" : 65,
"birth" : "1961/04/04",
"describe" : "我不是历史的关羽",
"phone" : 13579642589
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "关菲菲",
"age" : 50,
"birth" : "1981/05/18",
"describe" : "王者荣耀策划师",
"phone" : 13517946268
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "8",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 12,
"birth" : "2008/04/05",
"describe" : "我也叫柯莉堃",
"phone" : 18115974684
}
}
]
},
"aggregations" : {
"group" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "柯莉堃",
"doc_count" : 2
},
{
"key" : "上官婉儿",
"doc_count" : 1
},
{
"key" : "关羽",
"doc_count" : 1
},
{
"key" : "关菲菲",
"doc_count" : 1
},
{
"key" : "刘德华",
"doc_count" : 1
},
{
"key" : "王宝强",
"doc_count" : 1
},
{
"key" : "肖战",
"doc_count" : 1
}
]
}
}
}范围统计
根据一个数值字段的范围统计个数。
#数值范围统计
GET /persion/_search
{
"aggs": {
"agg": {
"range": {
"field": "age", #需要进行统计的字段
"ranges": [
{
"to":10 #从最小的到10岁
},
{
"from": 10, #从10岁,包含10岁
"to": 30 #到30岁,不包含30岁
},
{
"from":30 #从30到最大的
}
]
}
}
}
}
#时间范围统计
GET /persion/_search
{
"aggs": {
"agg": {
"date_range": {
"field": "birth",
"format": "yyyy", #格式化时间字段
"ranges": [
{
"from": "1996",
"to": "2003"
}
]
}
}
}
}
统计聚合查询
也就是统计各种数据,比如最大值,平均值啥的。
GET /persion/_search
{
"aggs": {
"agg": {
"extended_stats": {
"field": "age"
}
}
}
}
############ 结果 ##########
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 24,
"birth" : "1997/04/17",
"describe" : "我是柯莉堃啊",
"phone" : 18946297416
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "刘德华",
"age" : 60,
"birth" : "1973/01/12",
"describe" : "天王华仔",
"phone" : 15179461347
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "肖战",
"age" : 25,
"birth" : "1996/03/15",
"describe" : "招黑体质",
"phone" : 13594462687
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "王宝强",
"age" : 55,
"birth" : "1979/05/18",
"describe" : "无敌绿巨人",
"phone" : 18849532476
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "上官婉儿",
"age" : 18,
"birth" : "2002/02/02",
"describe" : "我不是一个法师",
"phone" : 15174692184
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "关羽",
"age" : 65,
"birth" : "1961/04/04",
"describe" : "我不是历史的关羽",
"phone" : 13579642589
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "关菲菲",
"age" : 50,
"birth" : "1981/05/18",
"describe" : "王者荣耀策划师",
"phone" : 13517946268
}
},
{
"_index" : "persion",
"_type" : "_doc",
"_id" : "8",
"_score" : 1.0,
"_source" : {
"name" : "柯莉堃",
"age" : 12,
"birth" : "2008/04/05",
"describe" : "我也叫柯莉堃",
"phone" : 18115974684
}
}
]
},
"aggregations" : {
"agg" : {
"count" : 8,
"min" : 12.0,
"max" : 65.0,
"avg" : 38.625,
"sum" : 309.0,
"sum_of_squares" : 15019.0,
"variance" : 385.484375,
"variance_population" : 385.484375,
"variance_sampling" : 440.55357142857144,
"std_deviation" : 19.633756008466644,
"std_deviation_population" : 19.633756008466644,
"std_deviation_sampling" : 20.98936805691328,
"std_deviation_bounds" : {
"upper" : 77.8925120169333,
"lower" : -0.6425120169332885,
"upper_population" : 77.8925120169333,
"lower_population" : -0.6425120169332885,
"upper_sampling" : 80.60373611382656,
"lower_sampling" : -3.3537361138265567
}
}
}
}20._cat命令
_cat可以查看es的各种信息。
查看索引信息
GET /_cat/indices #查看所有索引信息
GET /_cat/indices/索引名?v #查看指定索引信息
GET /_cat/allocation?v #查看资源情况7.filter查询操作:
filter的查询操作跟query查询操作类似;但是filter查询操作不会计算分数,并且查询结果会缓存下来.
GET hello/_search
{
"post_filter": { //filter查询
"match_all" : {} //查询类型
}
}8.script脚本:
es可以指定脚本来操作数据
"script": {
"lang": "...", //指定脚本语言
"source" | "id": "...", //脚本语句
"params": { ... } //参数
}POST hello/_update_by_query
{
"query" : {
"term" : {
"name" : "哆啦A梦"
}
},
"script": {
"lang": "painless",
"source": "ctx._source.count = params.count",
"params": {"count" : 500}
}
}
GET hello/_search
{
"query": {
"match_all" : {}
},
"_source": ["name","age"],
"script_fields": {
"type": {
"script": {
"lang": "painless",
"source": "if(doc['age'].value > 3){1}"
}
}
}
}11.java操作es(RestHighLevelClient)
1.创建操作es的客户端
//创建es客户端
RestHighLevelClient client;
@Before
public void init(){
HttpHost httpHost = new HttpHost("192.168.2.102",9200);
RestClientBuilder clientBuilder = RestClient.builder(httpHost);
client = new RestHighLevelClient(clientBuilder);
System.out.println("init执行");
}
@After
public void destroy() throws IOException {
client.close();
System.out.println("关闭资源");
}2.操作索引
1.创建索引
@Test
public void createIndex() throws IOException {
//设置索引
Settings.Builder setting = Settings.builder();
//设置索引分片数
setting.put("number_of_shards", 2);
//设置索引备份数
setting.put("number_of_replicas", 1);
//设置索引的mapping
XContentBuilder mapping = JsonXContent.contentBuilder();
mapping.startObject()
.startObject("properties")
.startObject("name")
.field("type", "text")
.endObject()
.startObject("age")
.field("type", "integer")
.endObject()
.startObject("birth")
.field("type","date")
.field("format", "yyyy-MM-dd")
.endObject()
.endObject()
.endObject();
//将setting和mapping封装到一个request对象中
CreateIndexRequest createIndexRequest = new CreateIndexRequest("persion_01");
createIndexRequest.settings(setting);
createIndexRequest.mapping(mapping);
//通过客户端发送请求给服务端
CreateIndexResponse response = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(response);
}2.删除索引
@Test
public void deleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("persion_01");
AcknowledgedResponse response = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(response);
}3.得到索引
@Test
public void getIndex() throws IOException {
GetIndexRequest getIndexRequest = new GetIndexRequest("book");
boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}3.操作文档
1.创建文档
@Test
public void createDoc() throws IOException {
Book book = new Book("火影", 00000001L);
//创建一个json转换类
ObjectMapper mapper = new JsonMapper();
//将Book对象转换成json数据
String json = mapper.writeValueAsString(book);
//创建一个请求
IndexRequest request = new IndexRequest();
request.index("book").id("3");
request.source(json, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}2.修改文档
@Test
public void updateDoc() throws IOException {
Map<String,Object> map = new HashMap<>();
map.put("name", "火影忍者");
UpdateRequest updateRequest = new UpdateRequest("book","3");
updateRequest.doc(map);
client.update(updateRequest, RequestOptions.DEFAULT);
}3.删除文档
@Test
public void deleteDoc() throws IOException {
DeleteRequest request = new DeleteRequest("book");
request.id("3");
client.delete(request, RequestOptions.DEFAULT);
}4.批量增加
@Test
public void bulkDoc() throws IOException {
Book book = new Book("西游记", 2L);
Book book1 = new Book("水浒传", 1L);
Book book2 = new Book("红楼梦", 3L);
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(book);
String json1 =mapper.writeValueAsString(book1);
String json2 =mapper.writeValueAsString(book2);
//批量添加文件
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("book").source(json, XContentType.JSON));
request.add(new IndexRequest("book").source(json1, XContentType.JSON));
request.add(new IndexRequest("book").source(json2, XContentType.JSON));
client.bulk(request, RequestOptions.DEFAULT);
}5.批量删除
@Test
public void bulkDeleteDoc() throws IOException {
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest("book","qN4Jq3cBZMG8vJ7fnene"));
request.add(new DeleteRequest("book","qd4Jq3cBZMG8vJ7fnene"));
request.add(new DeleteRequest("book","qt4Jq3cBZMG8vJ7fnene"));
client.bulk(request, RequestOptions.DEFAULT);
}4.查询操作
1.term查询
@Test
public void termQuery() throws IOException {
//创建搜索请求,并指定索引
SearchRequest request = new SearchRequest("persion");
//指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0).size(3);
builder.query(QueryBuilders.termQuery("name", "柯莉堃"));
//把查询条件加入搜索请求中
request.source(builder);
//执行查询
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}2.terms查询
@Test
public void termsQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0).size(3);
builder.query(QueryBuilders.termsQuery("name","刘德华","肖战","王宝强"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}3.match查询
@Test
public void matchQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0).size(3);
builder.query(QueryBuilders.matchQuery("describe", "不是"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}4.match_all查询
@Test
public void match_allQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchAllQuery());
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}5.matchbool查询
@Test
public void matchBoolQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("describe", "不是 历史").operator(Operator.AND));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}6.mulit_match查询
@Test
public void mulitMatchQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.multiMatchQuery("柯莉堃","name"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}7.id查询
@Test
public void idQuery() throws IOException {
GetRequest request = new GetRequest("persion", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsMap());
}8.ids查询
@Test
public void idsQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.idsQuery().addIds("1","2","3"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}9.scroll查询
@Test
public void scrollQuery() throws IOException {
//1.创建搜索请求
SearchRequest request = new SearchRequest("persion");
//2.指定scroll
request.scroll(new TimeValue(1L));
//3.指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.size(2);
builder.sort("age", SortOrder.ASC);
builder.query(QueryBuilders.matchAllQuery());
request.source(builder);
//4.查询首页
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
//5.得到scroll_id
String id = response.getScrollId();
//6.循环读取下一页
while (true){
SearchScrollRequest request1 = new SearchScrollRequest(id);
//7.指定scroll时间
request1.scroll(new TimeValue(1L));
//8.执行请求
SearchResponse response1 = client.scroll(request1, RequestOptions.DEFAULT);
//9.获取数据
SearchHit[] hits = response1.getHits().getHits();
//10.判断提出条件
if (hits == null || hits.length == 0){
break;
}
//11.取出数据
for (SearchHit hit : hits) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}
//12.删除scroll
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(id);
client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
}10.delete_by_query删除
@Test
public void deleteByQuery() throws IOException {
DeleteByQueryRequest request = new DeleteByQueryRequest("persion");
request.setQuery(QueryBuilders.termsQuery("name", "王宝强"));
client.deleteByQuery(request, RequestOptions.DEFAULT);
}11.bool查询
@Test
public void boolQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(QueryBuilders.termsQuery("name", "柯莉堃","刘德华","关菲菲"));
boolQueryBuilder.should(QueryBuilders.matchQuery("describe", "体质"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("age").gt("20").lt("30"));
builder.query(boolQueryBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}12.boosting查询
@Test
public void boostingQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
BoostingQueryBuilder boostingQueryBuilder = new BoostingQueryBuilder(
QueryBuilders.termsQuery("name", "柯莉堃","肖战","刘德华"),
QueryBuilders.matchQuery("describe", "体质")
).negativeBoost(0.5F);
builder.query(boostingQueryBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits()) {
Map<String, Object> data = hit.getSourceAsMap();
System.out.println(data);
}
}13.highlight查询
@Test
public void highLightQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("describe", "体质"));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("describe")
.fragmentSize(10)
.preTags("<front color='red'>")
.postTags("</front>");
builder.highlighter(highlightBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
Text[] fragments = highlightFields.get("describe").getFragments();
for (Text fragment : fragments) {
System.out.println(fragment.string());
}
}
}14.aggs查询
去重统计
@Test
public void aggsQuery() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
//指定agg查询,并设置查询名称
builder.aggregation(AggregationBuilders.cardinality("agg").field("name"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Cardinality agg = response.getAggregations().get("agg");
System.out.println(agg.getValue());
}
聚合统计
@Test
public void aggsextendsStates() throws IOException {
SearchRequest request = new SearchRequest("persion");
SearchSourceBuilder builder = new SearchSourceBuilder();
//指定agg查询,并设置查询名称
builder.aggregation(AggregationBuilders.extendedStats("agg").field("age"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
ExtendedStats agg = response.getAggregations().get("agg");
System.out.println(agg.getMax());
System.out.println(agg.getSum());
}12.java操作es(ElasticsearchClient)
在es7.15版本,RestHighLevelClient已经被弃用了,改用ElasticsearchClient
maven :
<dependency> <groupId>co.elastic.clients</groupId> <artifactId>elasticsearch-java</artifactId> <version>7.17.8</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.12.3</version> </dependency> lf you get ClassNotFoundException: jakarta.json.spi.JsonProvider <dependency> <groupId>jakarta.json</groupId> <artifactId>jakarta.json-api</artifactId> <version>2.0.1</version> </dependency>
1.创建客户端:
@Configuration
public class MyConfig {
@Bean
public ElasticsearchClient esClient() {
RestClient client = RestClient.builder(new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(client, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}测试客户端是否连接成功:
@Autowired
private ElasticsearchClient esClient;
@Test
void contextLoads() throws IOException {
BooleanResponse ping = esClient.ping();
System.out.println(ping.value());
}2.操作索引:
1.添加索引:
@Autowired
private ElasticsearchClient esClient;
@Test
void contextLoads() throws IOException {
CreateIndexResponse createIndexResponse = esClient.indices().create(i -> i
.index("haha") //指定索引名称
.aliases("my_haha", new Alias.Builder().isWriteIndex(true).build()) //指定索引别名
.settings(s -> s.index(set -> set
.numberOfShards("2") //指定分片数量
.numberOfReplicas("1") //指定备份分片数
)
) //指定setting
.mappings(m -> m
.dynamic(DynamicMapping.Strict) //指定动态映射的模式
.properties("name", p -> p.keyword(KeywordProperty.of(t -> t.ignoreAbove(10)))) //设置属性
.properties("describe", Property.of(t -> t.text(set -> set.analyzer("ik_max_word")))) //设置属性
.properties("count", p -> p.integer(set -> set)) //设置属性
) //指定映射
);
System.out.println(createIndexResponse.acknowledged()); //告知
}2.删除索引:
@Test
void test() throws IOException {
DeleteIndexResponse deleteIndexResponse = esClient.indices().delete(i -> i.index("idx"));
System.out.println(deleteIndexResponse.acknowledged());
}3.获取索引:
//判断索引是否存在
@Test
void test01() throws IOException {
BooleanResponse booleanResponse = esClient.indices().exists(i -> i.index("hello"));
System.out.println(booleanResponse.value());
}
//得到索引
@Test
void test02() throws IOException {
GetIndexResponse getIndexResponse = esClient.indices().get(i -> i.index("hello"));
System.out.println(getIndexResponse.result());
}4.修改索引:
@Test
void test03() throws IOException {
//修改setting
PutIndicesSettingsResponse putIndicesSettingsResponse = esClient.indices().putSettings(i -> i.index("hello").settings(set -> set.numberOfReplicas("0")));
//增加mapping-properties字段
PutMappingResponse putMappingResponse = esClient.indices().putMapping(i -> i.index("hello").properties("age", set -> set.integer(s -> s)));
//修改别名
DeleteAliasResponse deleteAliasResponse = esClient.indices().deleteAlias(i -> i.index("hello").name("my_hello"));
//添加别名
PutAliasResponse putAliasResponse = esClient.indices().putAlias(i -> i.index("hello").name("my_hello").isWriteIndex(true));
}3.操作文档:
1.添加文档:
//仅仅只能添加文档,如果文档id已经存在,则会报错
@Test
void test05() throws IOException {
Map<String, Object> map = new HashMap<>();
map.put("name", "哆啦A梦");
map.put("age", "16");
CreateResponse createResponse = esClient.create(i -> i.index("hello").type("_doc").id("2").document(map));
System.out.println(createResponse.result().jsonValue());
}
//添加文档,如果文档id存在,则直接覆盖
@Test
void test04() throws IOException {
Map<String, Object> map = new HashMap<>();
map.put("name", "哆啦A梦");
map.put("age", "16");
IndexResponse indexResponse = esClient.index(i -> i.index("hello").type("_doc").id("2").document(map));
System.out.println(indexResponse.result().jsonValue());
}2.修改文档:
//仅仅是修改文档,修改成功返回Updated,修改失败返回NoOp(没有选项呗修改)
@Test
void test06() throws IOException {
Map<String, Object> map = new HashMap<>();
map.put("name", "哆啦A梦");
map.put("age", "5");
UpdateResponse<Map> updateResponse = esClient.update(i -> i.index("hello").type("_doc").id("2").doc(map), Map.class);
System.out.println(updateResponse.result());
}3.删除文档:
@Test
void test07() throws IOException {
DeleteResponse deleteResponse = esClient.delete(i -> i.index("class").type("_doc").id("1"));
System.out.println(deleteResponse.result());
}4.批量增加:
@Test
void test08() throws IOException {
Map<String, Object> map = new HashMap<>();
map.put("name", "哆啦A梦");
map.put("age", "5");
List<BulkOperation> list = new ArrayList<>();
list.add(BulkOperation.of(o -> o.index(d -> d.index("hello").id("3").document(map))));
list.add(BulkOperation.of(o -> o.index(d -> d.index("hello").id("4").document(map))));
list.add(BulkOperation.of(o -> o.index(d -> d.index("hello").id("5").document(map))));
BulkResponse bulkResponse = esClient.bulk(i -> i.operations(list));
System.out.println(bulkResponse.errors());
}5.批量删除:
@Test
void test09() throws IOException {
List<BulkOperation> list = new ArrayList<>();
list.add(BulkOperation.of(o -> o.delete(d -> d.index("hello").id("3"))));
list.add(BulkOperation.of(o -> o.delete(d -> d.index("hello").id("4"))));
list.add(BulkOperation.of(o -> o.delete(d -> d.index("hello").id("5"))));
BulkResponse bulkResponse = esClient.bulk(i -> i.operations(list));
System.out.println(bulkResponse.items());
}4.查询操作:
1.term查询:
@Test
void test10() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i.index("class").query(s -> s.term(p -> p.field("name").value("火箭"))), Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) { //遍历击中的每条数据
System.out.println(hit.source());
}
}2.terms查询:
//某列查询多值,or关系
@Test
void test11() throws IOException {
List<FieldValue> list = new ArrayList<>();
list.add(FieldValue.of("蜡笔小新"));
list.add(FieldValue.of("哆啦A梦"));
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("hello")
.query(q -> q.terms(t -> t.terms(v -> v.value(list)).field("name")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}3.match查询:
@Test
void test12() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.match(m -> m.field("describe").query("火箭")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}
//match多值查询
@Test
void test12() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.match(m -> m.field("describe").query("火箭 希望")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}4.match_all查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.matchAll(m -> m.boost(1.2f)))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
System.out.println(hit.score());
}
}5.multi_match查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.multiMatch(m -> m.query("希望 梦幻").fields("name","describe")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}6.id查询:
@Test
void test14() throws IOException {
GetResponse<Map> getResponse = esClient.get(i -> i.index("class").type("_doc").id("5"), Map.class);
Map source = getResponse.source();
System.out.println(source);
}7.ids查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.ids(s -> s.values("4","5")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}8.prefix查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.prefix(p -> p.field("name").value("火")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}9.fuzzy查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.fuzzy(f -> f.field("name").value("湖贝大学").fuzziness("auto")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}10.wildcard查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.wildcard(w -> w.field("name").value("湖*")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}11.range查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("hello")
.query(q -> q.range(r -> r.field("age").gte(JsonData.of(4)).lte(JsonData.of(20))))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}12.regexp查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("hello")
.query(q -> q.regexp(r -> r.field("name").value(".*A.")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}13.scroll查询:
//第一次查询
@Test
void test15() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(s -> s
.index("class")
.scroll(Time.of(t -> t.time("5m")))
.query(q -> q.matchAll(m -> m))
.size(2)
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
System.out.println(searchResponse.scrollId());
}
//第二次查询
@Test
void test16() throws IOException {
SearchResponse<Map> searchResponse = esClient.scroll(s -> s
.scroll(Time.of(t -> t.time("5m"))) .scrollId("FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlhJN1pJbjNDUkVtNGI3RFppdlNqZFEAAAAAAAAChBY3eE9taUJ4b1JtNm5tcU84bkxCeW93")
.scroll(Time.of(t -> t.time("1m")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}14._delete_by_query查询删除:
@Test
void test17() throws IOException {
DeleteByQueryResponse deleteByQueryResponse = esClient.deleteByQuery(q -> q
.index("class")
.query(s -> s
.term(t -> t
.field("name")
.value("一班")
)
)
);
System.out.println(deleteByQueryResponse.deleted());
}15._update_by_query查询修改:
@Test
void test18() throws IOException {
UpdateByQueryResponse updateByQueryResponse = esClient.updateByQuery(i -> i
.index("hello") //指定索引
.query(q -> q //指定查询操作
.term(t -> t
.field("name")
.value("哆啦A梦")
)
)
.script(s -> s //指定脚本
.inline(l -> l
.lang("painless") //指定脚本语言
.source("ctx._source.count = params.c") //脚本语句
.params("c", JsonData.of(1000)) //参数
)
)
);
System.out.println(updateByQueryResponse.updated());
}16.bool查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q
.bool(b -> b
.must(m -> m
.match(t -> t
.field("describe")
.query("葵花 希望")
)
)
.should(s -> s
.term(t -> t
.field("name")
.value("火箭")
)
)
)
)
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}17.boosting查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.boosting(b -> b
.positive(p -> p
.match(m -> m
.field("describe")
.query("葵花 希望")
)
)
.negative(n -> n
.term(t -> t
.field("name")
.value("火箭")
)
)
.negativeBoost(0.2d)
)
)
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.score());
System.out.println(hit.source());
}
}18.highlight查询:
@Test
void test13() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q.match(m -> m.field("describe").query("葵花 希望")))
.highlight(h -> h.fields("describe",
l -> l.preTags("<span color='red'>").postTags("</span>")))
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
System.out.println(hit.highlight());
}
}19.分页查询:
@Test
void test12() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i //搜索请求
.index("class") //索引
.query(q -> q.matchAll(m -> m))
.from(0) //起始数据
.size(3) //页大小
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}20.排序查询:
@Test
void test12() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i //搜索请求
.index("class") //索引
.query(q -> q.matchAll(m -> m))
.sort(s -> s.field(f -> f.field("code").order(SortOrder.Desc))) //页大小
, Map.class);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(hit.source());
}
}21.聚合查询:
查询数据数:
@Test
void test19() throws IOException {
CountResponse countResponse = esClient.count(i -> i.index("class"));
System.out.println(countResponse.count());
}基数查询:
@Test
void test19() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.query(q -> q
.match(m -> m
.field("describe")
.query("葵花")
)
)
.aggregations("agg", a -> a.cardinality(c -> c.field("stu_count")))
, Map.class);
for (Map.Entry<String, Aggregate> entry : searchResponse.aggregations().entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue().cardinality().value());
}
}统计字段:
@Test
void test19() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.aggregations("agg", a -> a.valueCount(v -> v.field("stu_count")))
, Map.class);
for (Map.Entry<String, Aggregate> entry : searchResponse.aggregations().entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue().valueCount().value());
}
}累加:
@Test
void test19() throws IOException {
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("class")
.aggregations("agg", a -> a.sum(s -> s.field("stu_count")))
, Map.class);
for (Map.Entry<String, Aggregate> entry : searchResponse.aggregations().entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue().sum().value());
}
}分组查询:
void test19() throws IOException {
Map<String, SortOrder> map = new HashMap<>();
map.put("_count", SortOrder.Desc);
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("hello")
.aggregations("agg", a -> a.terms(t -> t.field("name")))
, Map.class);
for (StringTermsBucket agg : searchResponse.aggregations().get("agg").sterms().buckets().array()) {
System.out.println(agg.key() + "=" + agg.docCount());
}
}
//根据a.terms(t -> t.field("name")字段类型不同,返回的terms对象分为:
//sterms() ====> StringTermsBucket
//lterms() ====> LongTermsBucket
//dterms() ====> DoubleTermsBucket范围查询:
@Test
void test19() throws IOException {
Map<String, SortOrder> map = new HashMap<>();
map.put("_count", SortOrder.Desc);
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("hello")
.aggregations("agg", a -> a.range(r -> r
.field("age")
.ranges(s -> s.from("1").to("10"))))
, Map.class);
for (RangeBucket agg : searchResponse.aggregations().get("agg").range().buckets().array()) {
System.out.println(agg.key() + "=" + agg.docCount());
}
}统计查询:
@Test
void test20() throws IOException {
Map<String, SortOrder> map = new HashMap<>();
map.put("_count", SortOrder.Desc);
SearchResponse<Map> searchResponse = esClient.search(i -> i
.index("hello")
.aggregations("agg", a -> a.stats(s -> s.field("age")))
, Map.class);
StatsAggregate agg = searchResponse.aggregations().get("agg").stats();
System.out.println(agg.max());
System.out.println(agg.min());
System.out.println(agg.sum());
System.out.println(agg.avg());
System.out.println(agg.count());
}22.重建索引:
//重建索引
@Test
void test22() throws IOException {
Map<String, Property> map = new HashMap<>();
map.put("name", Property.of(p -> p.keyword(k -> k.ignoreAbove(5))));
map.put("describe", Property.of(p -> p.text(t -> t.analyzer("ik_max_word"))));
map.put("age", Property.of(p -> p.integer(i -> i)));
map.put("count", Property.of(p -> p.long_(l -> l)));
CreateIndexResponse createIndexResponse = esClient.indices().create(i -> i
.index("hellos")
.settings(s -> s
.numberOfShards("1")
.numberOfReplicas("1")
)
.mappings(m -> m
.dynamic(DynamicMapping.Strict)
.properties(map)
)
.aliases("my_hellos", Alias.of(a -> a.isWriteIndex(true)))
);
System.out.println(createIndexResponse.acknowledged());
}
//迁移数据
@Test
void test23() throws IOException {
ReindexResponse reindexResponse = esClient.reindex(r -> r
.source(s -> s.index("hello") //源索引
)
.dest(d -> d.index("hellos")) //目的索引
);
System.out.println(reindexResponse.batches());
}
