Mysql索引失效情况
1.为什么需要进行sql优化?
在日常开发中我们经常会遇到sql查询慢的情况,针对sql查询慢sql优化是我们需要面对的问题;在sql优化中建立合适的索引是非常重要的。
2.什么是索引?
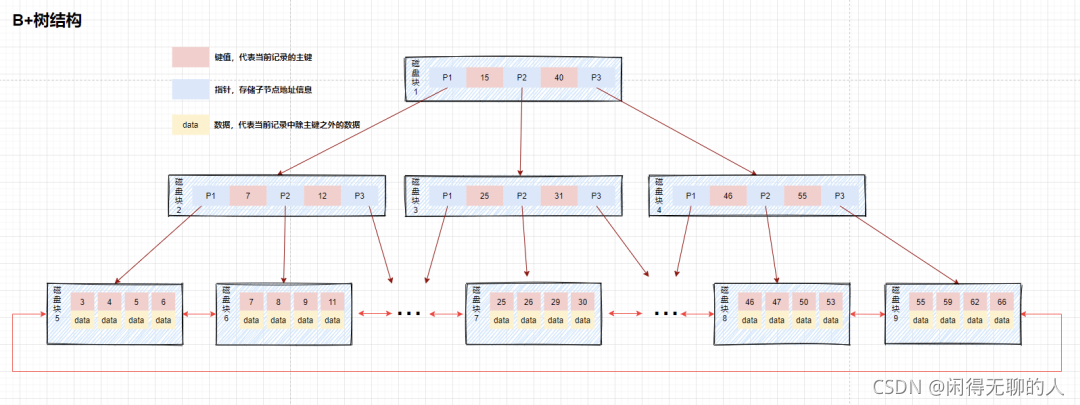
索引就是一种数据结构,用于快速查找数据的,一般这种数据结构有分叉树、hash表、跳表等;在Mysql中的索引主要就是B+树这种数据结构,B+树的特征是所有的数据都在叶子节点上,并且根节点到每一个叶子节点的层高是一样的,所有当我们查询每一个数据的时候它的查询速度都是一样的,叶子节点双向链表进行连接,进行范围查询的时候会很大的优势;
3.创建索引的要求:
我们在创建索引的时候不能随便创建,要分析那些列需要被创建索引,建立太多或者不恰当的索引都会影响我们查询、修改、删除数据的效率。
1)不经常使用的字段不要建立索引;
2)区分度低的字段不要建立索引,如性别字段;
3)更新比较频繁的字段不要建立索引。
符合以上规则的字段建议不要建立索引;
符合以下规则字段可考虑建立索引:
1)经常被用于查询的字段;
2)被用于联表查询的字段;
3)被用于排序的字段;
4)被用于分组的字段。
我们在建立索引的时候最好是建立复合索引,复合索引可以覆盖索引查询,索引使用的也更加充分。
3.索引失效场景
不恰当的使用索引会导致索引失效,此时不但不能加快查询速度,反而还会影响增删改的速度;
创建一个``test`表:
CREATE TABLE `test` (
`id` int NOT NULL AUTO_INCREMENT,
`a` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`b` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`c` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`d` int DEFAULT NULL,
`e` int DEFAULT NULL,
`f` int DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;创建索引idx_a_b_c:
CREATE index idx_a_b_c on test(a, b, c) 创建索引idx_d_e_f:
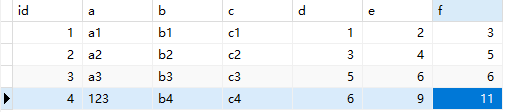
CREATE index idx_d_e_f on test(d, e, f) 数据:
1 尽量满足全值匹配:
EXPLAIN SELECT * FROM test WHERE a = 'a1';
EXPLAIN SELECT * FROM test WHERE a = 'a1' and b = 'b1';
EXPLAIN SELECT * FROM test WHERE a = 'a1' and b = 'b1' and c = 'c1';
我们可以看到查询使用到的索引列越多,key_len数值越大说明索引使用的越充分。
2 满足最左前缀法则:
EXPLAIN SELECT * FROM test WHERE b = 'b1' and c = 'c1';
当我们跳过a列查询的时候发现此时索引失效;
EXPLAIN SELECT * FROM test WHERE a = 'a1' and c = 'c1';
当我们跳过b列发现索引虽然使用了,但是只使用了一列,那就是a列;
EXPLAIN SELECT * FROM test WHERE c = 'c1';
当我们直接跳过a、b查询c此时索引是失效的;
以上我们能够看出在使用索引时需要满足最左前缀法则,如果索引中的哪个列没有使用到,那么后面的索引列都会失效。
EXPLAIN SELECT a, b FROM test WHERE c = 'c1';
当我们使用了覆盖索引,那么此时查询时条件是可以跳过索引中最前面的列的。
3 索引列计算、函数导致索引失效:
EXPLAIN SELECT * FROM test WHERE LEFT(a, 1) = 'a'
以上我们看到对索引列a使用函数会导致索引失效;
EXPLAIN SELECT * FROM test WHERE d = 2
EXPLAIN SELECT * FROM test WHERE d + 1 = 2
以上我们可以看到对索引列d进行计算也是会导致索引失效的。
EXPLAIN SELECT d FROM test WHERE d + 1 = 2
EXPLAIN SELECT a FROM test WHERE LEFT(a, 1) = 'a'
当我们使用覆盖索引我们能看到虽然我们对列进行了计算和使用了函数,但是索引依旧生效了。
4 类型转换导致索引失效:
EXPLAIN SELECT * FROM test WHERE a = '123'
EXPLAIN SELECT * FROM test WHERE a = 123
我们可以看到a是字符类型使用数值进行查询会导致索引失效,因为Mysql在比较字符串和数值的时候会将字符串先转成数值在进行比较,这个转换是会全表扫描的。
EXPLAIN SELECT a FROM test WHERE a = 123
当我们使用覆盖索引的时候我们会发现将a和数值进行比较也会走索引。
5 索引列范围查询右边列失效:
idx_d_e_f全部生效的情况:
EXPLAIN SELECT * FROM test WHERE d = 1 and e = 2 and f = 3
当索引第一列为范围查询时,整个idx_d_e_f全部失效:
EXPLAIN SELECT * FROM test WHERE d > 1 and e = 2 and f = 3
当索引第二列为范围查询时候,索引只使用到了d和e列:
EXPLAIN SELECT * FROM test WHERE d = 1 and e > 2 and f = 3
当第三列为范围查询时,整个索引都生效了:
EXPLAIN SELECT * FROM test WHERE d = 1 and e = 2 and f > 3
当使用覆盖索引时,我们会发现原本第一列使用范围查询会导致整个索引失效的情况变为了使用索引d列:
EXPLAIN SELECT d,e,f FROM test WHERE d > 1 and e = 2 and f = 3
覆盖索引的情况下第二列为范围查询,我们发现情况跟没使用覆盖索引是一样的只有d和e使用到了索引:
EXPLAIN SELECT d,e,f FROM test WHERE d = 1 and e > 2 and f = 3
通过以上案例我们发现范围查询列最好放在索引的最后面。
6 不等于导致索引失效:
在Mysql中!=和<>这两个符号表示不等于,由于不等于不是精确查询,与其遍历索引树再进行回表操作,倒不如直接全表扫描:
EXPLAIN SELECT * FROM test WHERE d != 1
EXPLAIN SELECT * FROM test WHERE d <> 1
以上我们可以看到不等于是不会使用到索引的;
当我们使用覆盖索引时,此时是会使用到索引的,因为此时的不等于操作不需要回表了,因此直接遍历索引树的数据就行;
EXPLAIN SELECT d FROM test WHERE d != 1
7 is not null导致索引失效:
在Mysql中is null是会使用到索引的:
EXPLAIN SELECT * FROM test WHERE a is null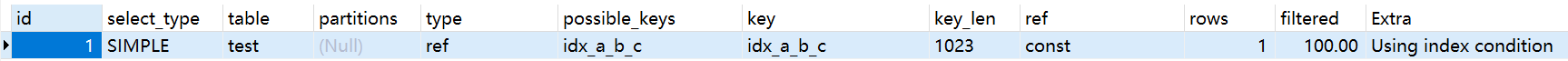
但是is not null是不会使用到索引的:
EXPLAIN SELECT * FROM test WHERE a is not null
单值索引只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
由于索引中记录的都是每一列不为空的数据,只要其中一列为空就不被记录索引,is null直接可以找到没有被索引树记录的数据,而is not null无法确认到底是索引列上的那一列不为空,所以会导致全表扫描。
索引列为
null的数据也是会被添加到B+树的,并且位置在最左边,所以is null可以走索引;至于为什么
is not null不能走索引?是因为Mysql优化器对是否走索引进行了计算,计算结果是全表扫描的效率高于走索引的效率;
为什么呐?
因为假如我们
is not null走索引,其实是先遍历整个二级索引树,再将二级索引树上匹配不为空的id拿到一级索引树上去匹配数据,整个操作的执行效率不如直接遍历整个一级索引高,索引Mysql优化器选择了全表扫描。但是当Mysql优化器计算出走索引的效率高于全部扫描时还是会走索引的。因此
not is null不走索引不是绝对的。

当使用覆盖索引的时候,is not null是可以使用到索引的:
EXPLAIN SELECT a FROM test WHERE a is not null
8 like导致索引失效:
EXPLAIN SELECT * FROM test WHERE a like 'a'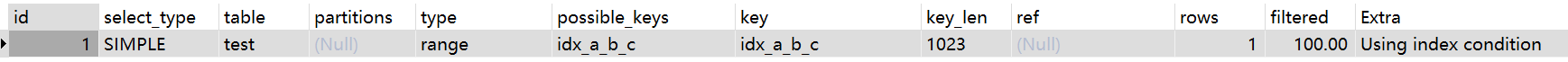
当使用前置%时候会导致索引失效:
EXPLAIN SELECT * FROM test WHERE a like '%a'
当使用覆盖索引的时候可以最大层度的使用索引:
EXPLAIN SELECT a FROM test WHERE a like '%a'
not like无法使用索引:
EXPLAIN SELECT * FROM test WHERE a not like 'a'
但是使用覆盖索引时not like是可以使用索引的:
EXPLAIN SELECT a FROM test WHERE a not like 'a'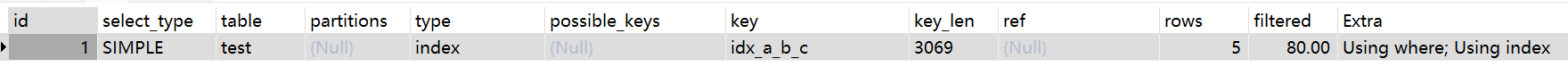
虽然在覆盖索引的情况下
like %和not like使用了索引,但是是扫描整个索引树的数据。
9 or导致索引失效:
or会导致索引的失效:
EXPLAIN SELECT * FROM test WHERE a = 'a1' or a = 'a2'
EXPLAIN SELECT * FROM test WHERE a = 'a1' or b = 'b2'
但是id字段使用or主键索引是不会失效的:
EXPLAIN SELECT * FROM test WHERE id = 1 or id = 2
在Mysql 8中如果or前面的字段和后面的字段都有索引,那么是可以使用联合索引index_merge:
覆盖索引的情况下or可以使用索引:
EXPLAIN SELECT a FROM test WHERE a = 'a1' or a = 'a2'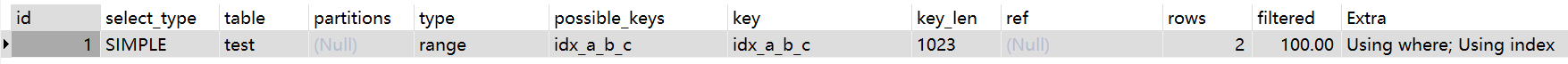
EXPLAIN SELECT a,b,c FROM test WHERE a = 'a1' or b = 'b2'
10 不同字符集导致索引失败:
不同的字符集进行比较前需要进行转换会造成索引失效。
数据库和表的字符集统一使用utf8mb4。统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。
4.总结:
Mysql中建立索引最好是复合索引;
使用索引最好的全值匹配,这样索引使用的越充分;
需要满足最左前缀法则;
不要在索引列使用任何函数或者计算;
索引列进行比较时类型一定要匹配,不然会隐式类型转换导致索引失效;
范围查询放到索引列最右边;
索引字段最好设置默认值不要为
null;避免使用
is not null、not like和or;使用
like时候%不要放在最前面,实在需要模糊查询建议使用专门搜索框架入Elasticsearch;在查询时候尽量不要写
*需要什么字段select什么字段,最好是用到覆盖索引。

