Spring二级缓存就能解决循环依赖为什么非弄个三级缓存
看 Spring 源码或者去面试,循环依赖出场率很高。
很多人都知道 Spring 是靠三级缓存来解决这个问题的,但只要稍微深究一下,就会发现一个好玩的事情:其实二级缓存就已经足够解决循环依赖了。
那 Spring 为什么还要大费周折地引入第三级缓存?多加这一层缓存,到底是为了解决什么痛点呢?
什么是 Spring 的三级缓存?
Spring 所谓的三级缓存其实就是 DefaultSingletonBeanRegistry 类里的三个 Map:
一级缓存(singletonObjects):存放完全初始化好的 Bean,拿出来就能直接用。
二级缓存(earlySingletonObjects):存放半成品 Bean,也就是刚通过 new 实例化出来,但还没有注入属性、没有执行初始化方法的 Bean。
三级缓存(singletonFactories):存放 Bean 工厂 ObjectFactory,这里面存的不是实例,而是一个可以用来创建 Bean 的 Lambda 回调函数。
为什么二级缓存就能解决循环依赖?
如果不考虑 AOP 代理,单纯是普通 Bean 之间的循环依赖,二级缓存确实完全够用了。
我们把 Bean 的生命周期拆成两步:
实例化:相当于在 JVM 里 new 了一个对象,分配了内存空间,但属性全是默认空值。
初始化:给对象注入属性,执行各种 init 方法。
假设服务 A 和服务 B 互相依赖,只用二级缓存的运转流程非常简单:
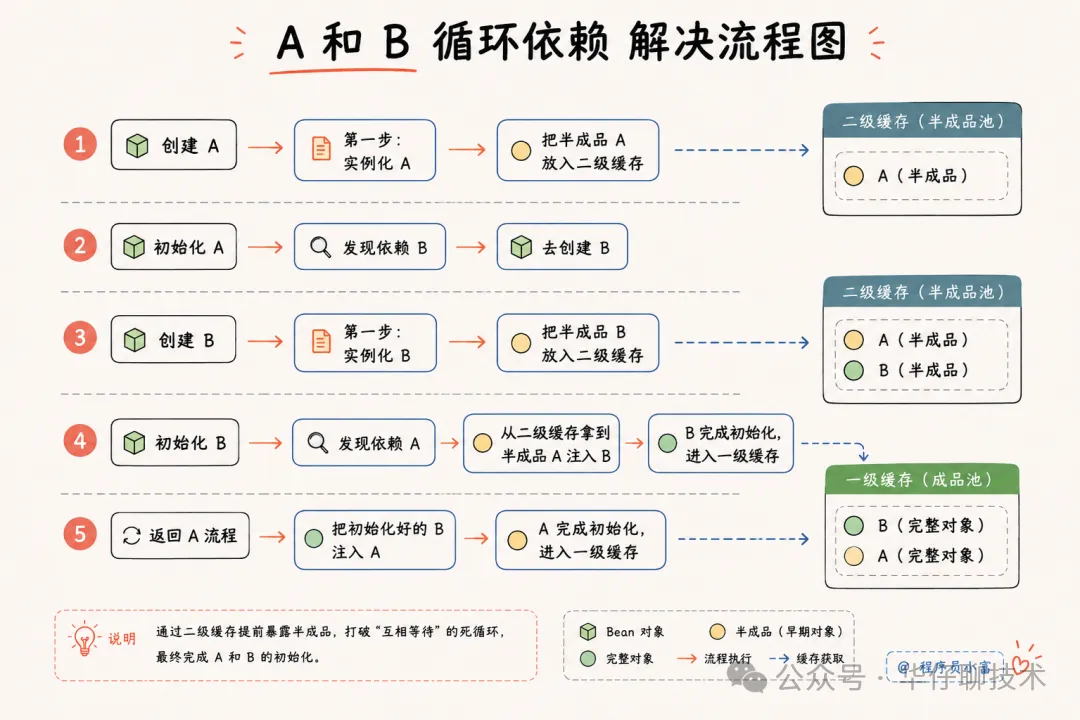
在这个流程里,B 在初始化时需要 A,虽然 A 还没初始化完,但已经在二级缓存里挂名了。B 拿到 A 的引用直接注入,顺利完成初始化。
整个循环依赖在二级缓存这一层就已经解决了。
为什么非要引入三级缓存?
既然二级缓存能搞定,为什么还要整出个三级缓存?
主要是为了解决:AOP 面向切面编程
Spring 的标准生命周期里,AOP 代理对象的创建是在很靠后的阶段完成的,也就是在 Bean 初始化之后的后置处理器(AnnotationAwareAspectJAutoProxyCreator)里去创建代理对象。
正常情况下,Spring 肯定希望所有 Bean 都走完标准生命周期,也就是先创建原始对象,然后注入属性,最后再生成代理对象。
但是发生循环依赖,问题就来了。比如 A 和 B 互相依赖,且 A 需要被 AOP 代理:
- B 初始化时需要注入 A。
- 如果直接从二级缓存里拿,拿到的只能是 A 的原始对象,而不是 A 的代理对象。
- 等到 A 自己走完后续生命周期生成代理对象后,B 里持有的依然是那个原始的 A,这就出大问题了。
如果不用三级缓存,强行用二级缓存解决这个问题呢?
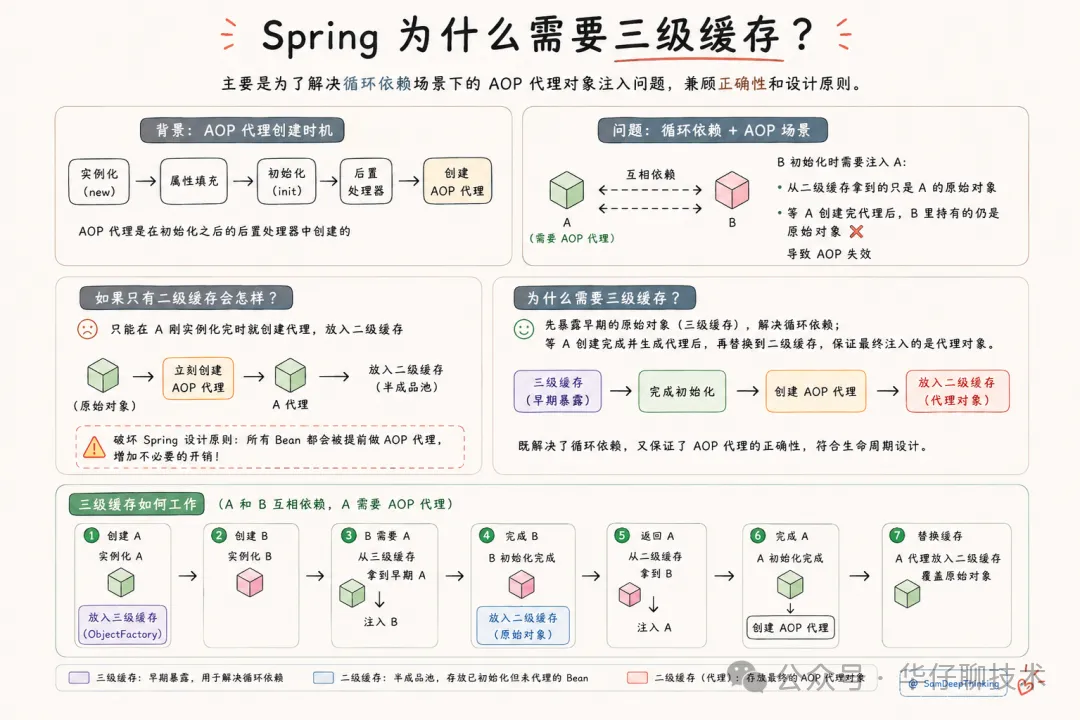
那就只能在 A 刚实例化完的时候,立刻去给它创建 AOP 代理,然后把代理对象塞进二级缓存。
但这会严重破坏 Spring 的设计原则:不管有没有循环依赖,所有 Bean 在实例化之后都得提前进行 AOP 代理。 这违背了 Spring 声明周期设计的初衷,还会增加很多不必要的提前代理开销。
三级缓存怎么解决这个冲突?
Spring 引入三级缓存,本质上是做了一次延迟加载,三级缓存里存的不是 Bean 实例,而是一个工厂回调:
// A 实例化后,提前暴露一个 ObjectFactory 放入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));这个 Lambda 表达式里的 getEarlyBeanReference 方法就是解题的关键,它做的事情很简单:如果这个 Bean 配置了 AOP,那就去创建它的代理对象;如果没有,就返回原对象。
最妙的地方在于,这个工厂回调在平时是根本不会被执行的,只有当发生循环依赖,B 在初始化去向 Spring 要 A 的时候,Spring 才会去调用三级缓存里的 getObject() 回调。
// Spring 获取单例 Bean 的三重检查简化逻辑
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 1. 先查一级缓存(成品)
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 2. 一级没有,查二级缓存(半成品)
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 3. 二级没有,从三级缓存拿 ObjectFactory 并执行回调
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject(); // 在这里才真正触发 AOP 代理创建
// 4. 将生成的代理对象(或原对象)放入二级缓存,并移除三级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}我们可以把这个协同过程梳理成以下几步:
- A 实例化完成:Spring 把 A 的原始对象包装成
ObjectFactory丢进三级缓存。此时没有发生 AOP 代理。 - A 注入属性需要 B:去创建 B。
- B 注入属性需要 A:B 调用
getSingleton(A)。 - 触发延迟执行:发现一级、二级缓存都没有 A,但三级缓存里有 A 的工厂。调用工厂的
getObject()。 - 按需生成代理:A 的工厂发现 A 需要做 AOP 代理,于是提前生成 A 的代理对象(假设是 A_Proxy),并把它塞进二级缓存。B 顺利拿到 A_Proxy 并注入成功。
- B 完成初始化:进入一级缓存。
- 返回 A 流程:A 注入 B。A 继续走完后续生命周期,在初始化后置处理阶段,A 发现自己已经提前做过 AOP 代理了(在二级缓存里能找到对应的 A_Proxy),于是直接返回二级缓存里的 A_Proxy
- A 完成初始化:A_Proxy 进入一级缓存。
如果没有循环依赖,三级缓存里的工厂回调就一直是个“死代码”,Bean 会规规矩矩地走到最后才生成代理对象。
只有在真正发生循环依赖时,三级缓存才会被激活,用来临时提前生成代理对象,并缓存到二级缓存中供依赖者使用。
说在最后
其实说白了,三级缓存的设计取舍只有一句话:
三级缓存存工厂回调,是为了在不破坏 Bean 标准生命周期的前提下,延迟且按需地处理 AOP 代理。
二级缓存解决的是如何提早暴露半成品的问题,三级缓存解决的是如何提早暴露被 AOP 代理后的半成品的问题。

